





-
How Do You Teach an AI Model to Reason? With Humans
AI models are advancing at a rapid rate and scale.
But what might they lack thathumans don’t? Common sense: an understanding, developed through real-world experiences, that birds can’t fly backwards, mirrors are reflective and ice melts into water.
While such principles seem obvious to humans, they must be taught to AI models tasked with accurately answering complex questions and navigating unpredictable physical environments, such as industrial warehouses or roads.
NVIDIA is tackling this challenge by developing a set of tests to coach AI models on the limitations of the physical world. In other words, to teach AI common sense.
These tests are used to develop reasoning models such as NVIDIA Cosmos Reason, an open reasoning vision language modelused for physical AI applications that are proficient in generating temporally grounded responses. Cosmos Reason just topped the physical reasoning leaderboard on Hugging Face.
Cosmos Reason is unique compared with previous VLMs as it’s designed to accelerate physical AI development for fields such as robotics, autonomous vehicles and smart spaces. The model can infer and reason through unprecedented scenarios using physical common-sense knowledge.
For models to understand complex environments — including industrial spaces and laboratories — they must start small. For example, in the test depicted below, the Cosmos Reason model is tasked with answering a multiple-choice question about the relative motion in the video:
Example from Cosmos Reason evaluation dataset
What Does Reasoning Look Like for an AI Model?
To develop their reasoning capabilities, NVIDIA models are being taught physical common sense about the real world via reinforcement learning.
For example, robots don’t intuitively know which way is left, right, up or down. They’re taught these spatial-temporal limitations through training. AI-powered robots used in safety testing, such as vehicle crash testing, must be taught to be aware of how their physical forms interact with their surroundings.
Without embedding common sense into the training of these robots, issues can arise in deployment.
“Without basic knowledge about the physical world, a robot may fall down or accidentally break something, causing danger to the surrounding people and environment,” said Yin Cui, a Cosmos Reason research scientist at NVIDIA.
Distilling human common sense about the physical world into models is how NVIDIA is bringing about the next generation of AI.
Enter the NVIDIA data factory team: a group of global analysts who come from various backgrounds — including bioengineering, business and linguistics. They’re working to develop, analyze and compile hundreds of thousands of data units that will be used to train generative AI models on how to reason.
The Data Curation Process
One of the NVIDIA data factory team’s projects focuses on the development of world foundation models for physical AI applications. These virtual environments create deep learning neural networks that are safer and more effective for training reasoning models, based on simulated domains.
It all starts with an NVIDIA annotation group that creates question-and-answer pairs based on video data. These videos are all from the real world and can include any type of footage, whether depicting chickens walking around in their coop or cars driving on a rural road.
For example, an annotator might ask about the video below: “The person uses which hand to cut the spaghetti?”
Example from Cosmos Reason evaluation dataset
The annotators then come up with four multiple choice answers labeled A, B, C and D. The model is fed the data and has to reason and choose the correct answer.
“We’re basically coming up with a test for the model,” said Cui. “All of our questions are multiple choice, like what students would see on a school exam.”
These question-and-answer pairs are then quality checked by NVIDIA analysts, such as Michelle Li.
Li has a background in public health and data analytics, which allows her to look at the broader purpose of the data she analyzes.
“For physical AI, we have a specific goal of wanting to train models on understanding the physical world, which helps me think about the bigger picture when I’m looking at the Q&A pairs and the types of questions that are being presented,” Li said. “I ask myself, do the Q&A pairs that I’m looking at align with our objectives for the guidelines that we have for the project?”
After this, the data is reviewed by the data factory leads of the project, who make sure it’s up to quality standards and ready to be sent to the Cosmos Reason research team. The scientists then feed the hundred thousands of data units — in this case the Q&A pairs — to the model, training it with reinforcement learning on the bounds and limitations of the physical world.
What Are the Applications of Reasoning AI?
Reasoning models are exceptional because they can make sense of their temporal space as well as predict outcomes. They can analyze a situation, come up with a thought web of probable outcomes and infer the most likely scenario.
Simply put, reasoning AI demonstrates humanlike thinking. It shows its work, giving the user insight into the logic behind its responses.
Users can ask these models to analyze a video such as of two cars driving on a road. When asked a question like, “What would happen if the cars were driving toward each other on the same lane?” the model can reason and determine the most probable outcome of the proposed scenario — for example, a car crash.
“We’re building a pioneering reasoning model focused on physical AI,” said Tsung-Yi Lin, a principal research scientist on the Cosmos Reason team at NVIDIA.
The data factory team’s ability to produce high-quality data will be imperative for driving the development of intelligent autonomous agents and physical AI systems that can safely interact with the real world as NVIDIA reasoning model innovation continues.
Preview NVDIA Cosmos-Reason1 or download the model on Hugging Face and GitHub.
#how #you #teach #model #reasonHow Do You Teach an AI Model to Reason? With HumansAI models are advancing at a rapid rate and scale. But what might they lack thathumans don’t? Common sense: an understanding, developed through real-world experiences, that birds can’t fly backwards, mirrors are reflective and ice melts into water. While such principles seem obvious to humans, they must be taught to AI models tasked with accurately answering complex questions and navigating unpredictable physical environments, such as industrial warehouses or roads. NVIDIA is tackling this challenge by developing a set of tests to coach AI models on the limitations of the physical world. In other words, to teach AI common sense. These tests are used to develop reasoning models such as NVIDIA Cosmos Reason, an open reasoning vision language modelused for physical AI applications that are proficient in generating temporally grounded responses. Cosmos Reason just topped the physical reasoning leaderboard on Hugging Face. Cosmos Reason is unique compared with previous VLMs as it’s designed to accelerate physical AI development for fields such as robotics, autonomous vehicles and smart spaces. The model can infer and reason through unprecedented scenarios using physical common-sense knowledge. For models to understand complex environments — including industrial spaces and laboratories — they must start small. For example, in the test depicted below, the Cosmos Reason model is tasked with answering a multiple-choice question about the relative motion in the video: Example from Cosmos Reason evaluation dataset What Does Reasoning Look Like for an AI Model? To develop their reasoning capabilities, NVIDIA models are being taught physical common sense about the real world via reinforcement learning. For example, robots don’t intuitively know which way is left, right, up or down. They’re taught these spatial-temporal limitations through training. AI-powered robots used in safety testing, such as vehicle crash testing, must be taught to be aware of how their physical forms interact with their surroundings. Without embedding common sense into the training of these robots, issues can arise in deployment. “Without basic knowledge about the physical world, a robot may fall down or accidentally break something, causing danger to the surrounding people and environment,” said Yin Cui, a Cosmos Reason research scientist at NVIDIA. Distilling human common sense about the physical world into models is how NVIDIA is bringing about the next generation of AI. Enter the NVIDIA data factory team: a group of global analysts who come from various backgrounds — including bioengineering, business and linguistics. They’re working to develop, analyze and compile hundreds of thousands of data units that will be used to train generative AI models on how to reason. The Data Curation Process One of the NVIDIA data factory team’s projects focuses on the development of world foundation models for physical AI applications. These virtual environments create deep learning neural networks that are safer and more effective for training reasoning models, based on simulated domains. It all starts with an NVIDIA annotation group that creates question-and-answer pairs based on video data. These videos are all from the real world and can include any type of footage, whether depicting chickens walking around in their coop or cars driving on a rural road. For example, an annotator might ask about the video below: “The person uses which hand to cut the spaghetti?” Example from Cosmos Reason evaluation dataset The annotators then come up with four multiple choice answers labeled A, B, C and D. The model is fed the data and has to reason and choose the correct answer. “We’re basically coming up with a test for the model,” said Cui. “All of our questions are multiple choice, like what students would see on a school exam.” These question-and-answer pairs are then quality checked by NVIDIA analysts, such as Michelle Li. Li has a background in public health and data analytics, which allows her to look at the broader purpose of the data she analyzes. “For physical AI, we have a specific goal of wanting to train models on understanding the physical world, which helps me think about the bigger picture when I’m looking at the Q&A pairs and the types of questions that are being presented,” Li said. “I ask myself, do the Q&A pairs that I’m looking at align with our objectives for the guidelines that we have for the project?” After this, the data is reviewed by the data factory leads of the project, who make sure it’s up to quality standards and ready to be sent to the Cosmos Reason research team. The scientists then feed the hundred thousands of data units — in this case the Q&A pairs — to the model, training it with reinforcement learning on the bounds and limitations of the physical world. What Are the Applications of Reasoning AI? Reasoning models are exceptional because they can make sense of their temporal space as well as predict outcomes. They can analyze a situation, come up with a thought web of probable outcomes and infer the most likely scenario. Simply put, reasoning AI demonstrates humanlike thinking. It shows its work, giving the user insight into the logic behind its responses. Users can ask these models to analyze a video such as of two cars driving on a road. When asked a question like, “What would happen if the cars were driving toward each other on the same lane?” the model can reason and determine the most probable outcome of the proposed scenario — for example, a car crash. “We’re building a pioneering reasoning model focused on physical AI,” said Tsung-Yi Lin, a principal research scientist on the Cosmos Reason team at NVIDIA. The data factory team’s ability to produce high-quality data will be imperative for driving the development of intelligent autonomous agents and physical AI systems that can safely interact with the real world as NVIDIA reasoning model innovation continues. Preview NVDIA Cosmos-Reason1 or download the model on Hugging Face and GitHub. #how #you #teach #model #reason· 2 Comments ·0 Shares


 29
29
-
Drop Into the Battle: ‘Gears of War: Reloaded’ Launches on GeForce NOW
Brace yourself, COGs — the Locusts aren’t the only thing rising up. The Coalition’s legendary shooter Gears of War: Reloaded is launching day one on GeForce NOW.
But that’s just the start. This GFN Thursday, seven games join the GeForce NOW library, including Ubisoft’s The Rogue Prince of Persia, the electrifying 2D roguelike action-platformer.
More Grit, More Gears
Never skip leg day.
Chainsaws — check. Grizzled one-liners — absolutely. Gears of War: Reloaded is back, buffed and primed, remastered from the ground up in Unreal Engine 5. It’s the classic curb-stomping action gamers remember, now with visuals sharp enough to make the Locust run for cover. Form up and get loud.
Dive into battle with Marcus, Dom and the rest of Delta Squad to fight tooth and chainsaw to save humanity from the subterranean Locust Horde. Carve through the epic campaign solo or tag in friends for online co-op mode. The remastered version packs every blast, chainsaw duel and bro fist from the original — plus bonus campaign missions, multiplayer maps and more. Tackle battles with modern controls for franchise newcomers or classic controls for veterans — no grunt left behind.
Stream Gears of War: Reloaded on GeForce NOW and witness Unreal Engine’s best visuals without upgrading hardware. Run multiplayer with the lowest latency with an Ultimate membership, cross-play with the squad and see every crumbling wall and flying chunk — all from the cloud, effortlessly.
Greatest Leap Yet
Kick first, ask questions later.
The Rogue Prince of Persia 1.0 marks the game’s full release after months of early access, bringing refined parkour, polished combat, fresh content and the complete story of the rogue heir racing to reclaim his kingdom. Sprint, vault and wall-run through a reimagined Persia as the prince battles to undo a deadly curse and stop the invading Huns.
Each run is a new fight for survival, blending fluid platforming with swift, acrobatic combat. Leap over traps, chain stylish moves and wield an ever-expanding arsenal while unlocking medallions, upgrading gear and uncovering the truth behind the prince’s fall — and his shot at redemption.
On GeForce NOW, the adventure shines at its best with up to 4K 120 frames-per-second streaming. Land every parkour move with perfect timing thanks to ultralow latency and take the prince’s fight anywhere, instantly, on nearly any device.
Let’s Play Today
Catbots > Brainblobs.
Make sure to check out Chip ‘n Clawz vs. The Brainioids, a quirky action-strategy hybrid from X-COM creator Julian Gollop, where players control a clever inventor and his robo-cat to fight off an invasion of bizarre Brainioid aliens. Mix third-person action with real-time strategy while building bases, commanding bot armies and squishing rogue brains in solo and co-op modes, all wrapped in a colorful, comic-book world. Couch and online multiplayer, player vs. player battles and a humorous campaign make this a fresh, approachable take on the strategy genre.
In addition, members can look for the following:
Gears of War: ReloadedChip ‘n Clawz vs. The BrainioidsMake WayAmong Us 3DGatekeeperKnighticaNo Sleep for Kaname Date – From AI: THE SOMNIUM FILESWhat are you planning to play this weekend? Let us know on X or in the comments below.
This is a duo appreciation post.
Who are you locking in with?— NVIDIA GeForce NOWAugust 27, 2025
#drop #into #battle #gears #warDrop Into the Battle: ‘Gears of War: Reloaded’ Launches on GeForce NOWBrace yourself, COGs — the Locusts aren’t the only thing rising up. The Coalition’s legendary shooter Gears of War: Reloaded is launching day one on GeForce NOW. But that’s just the start. This GFN Thursday, seven games join the GeForce NOW library, including Ubisoft’s The Rogue Prince of Persia, the electrifying 2D roguelike action-platformer. More Grit, More Gears Never skip leg day. Chainsaws — check. Grizzled one-liners — absolutely. Gears of War: Reloaded is back, buffed and primed, remastered from the ground up in Unreal Engine 5. It’s the classic curb-stomping action gamers remember, now with visuals sharp enough to make the Locust run for cover. Form up and get loud. Dive into battle with Marcus, Dom and the rest of Delta Squad to fight tooth and chainsaw to save humanity from the subterranean Locust Horde. Carve through the epic campaign solo or tag in friends for online co-op mode. The remastered version packs every blast, chainsaw duel and bro fist from the original — plus bonus campaign missions, multiplayer maps and more. Tackle battles with modern controls for franchise newcomers or classic controls for veterans — no grunt left behind. Stream Gears of War: Reloaded on GeForce NOW and witness Unreal Engine’s best visuals without upgrading hardware. Run multiplayer with the lowest latency with an Ultimate membership, cross-play with the squad and see every crumbling wall and flying chunk — all from the cloud, effortlessly. Greatest Leap Yet Kick first, ask questions later. The Rogue Prince of Persia 1.0 marks the game’s full release after months of early access, bringing refined parkour, polished combat, fresh content and the complete story of the rogue heir racing to reclaim his kingdom. Sprint, vault and wall-run through a reimagined Persia as the prince battles to undo a deadly curse and stop the invading Huns. Each run is a new fight for survival, blending fluid platforming with swift, acrobatic combat. Leap over traps, chain stylish moves and wield an ever-expanding arsenal while unlocking medallions, upgrading gear and uncovering the truth behind the prince’s fall — and his shot at redemption. On GeForce NOW, the adventure shines at its best with up to 4K 120 frames-per-second streaming. Land every parkour move with perfect timing thanks to ultralow latency and take the prince’s fight anywhere, instantly, on nearly any device. Let’s Play Today Catbots > Brainblobs. Make sure to check out Chip ‘n Clawz vs. The Brainioids, a quirky action-strategy hybrid from X-COM creator Julian Gollop, where players control a clever inventor and his robo-cat to fight off an invasion of bizarre Brainioid aliens. Mix third-person action with real-time strategy while building bases, commanding bot armies and squishing rogue brains in solo and co-op modes, all wrapped in a colorful, comic-book world. Couch and online multiplayer, player vs. player battles and a humorous campaign make this a fresh, approachable take on the strategy genre. In addition, members can look for the following: Gears of War: ReloadedChip ‘n Clawz vs. The BrainioidsMake WayAmong Us 3DGatekeeperKnighticaNo Sleep for Kaname Date – From AI: THE SOMNIUM FILESWhat are you planning to play this weekend? Let us know on X or in the comments below. This is a duo appreciation post. Who are you locking in with?— NVIDIA GeForce NOWAugust 27, 2025 #drop #into #battle #gears #war· 2 Comments ·0 Shares
397
-
NVIDIA Jetson Thor Unlocks Real-Time Reasoning for General Robotics and Physical AI
Robots around the world are about to get a lot smarter as physical AI developers plug in NVIDIA Jetson Thor modules — new robotics computers that can serve as the brains for robotic systems across research and industry.
Robots demand rich sensor data and low-latency AI processing. Running real-time robotic applications requires significant AI compute and memory to handle concurrent data streams from multiple sensors. Jetson Thor, now in general availability, delivers 7.5x more AI compute, 3.1x more CPU performance and 2x more memory than its predecessor, the NVIDIA Jetson Orin, to make this possible on device.
This performance leap will enable roboticists to process high-speed sensor data and perform visual reasoning at the edge — workflows that were previously too slow to run in dynamic real-world environments. This opens new possibilities for multimodal AI applications such as humanoid robotics.
Agility Robotics, a leader in humanoid robotics, has integrated NVIDIA Jetson into the fifth generation of its robot, Digit — and plans to adopt Jetson Thor as the onboard compute platform for the sixth generation of Digit. This transition will enhance Digit’s real-time perception and decision-making capabilities, supporting increasingly complex AI skills and behaviors. Digit is commercially deployed and performs logistics tasks such as stacking, loading and palletizing in warehouse and manufacturing environments.
“The powerful edge processing offered by Jetson Thor will take Digit to the next level — enhancing its real-time responsiveness and expanding its abilities to a broader, more complex set of skills,” said Peggy Johnson, CEO of Agility Robotics. “With Jetson Thor, we can deliver the latest physical AI advancements to optimize operations across our customers’ warehouses and factories.”
Boston Dynamics — which has been building some of the industry’s most advanced robots for over 30 years — is integrating Jetson Thor into its humanoid robot Atlas, enabling Atlas to harness formerly server-level compute, AI workload acceleration, high-bandwidth data processing and significant memory on device.
Beyond humanoids, Jetson Thor will accelerate various robotic applications — such as surgical assistants, smart tractors, delivery robots, industrial manipulators and visual AI agents — with real-time inference on device for larger, more complex AI models.
A Giant Leap for Real-Time Robot Reasoning
Jetson Thor is built for generative reasoning models. It enables the next generation of physical AI agents — powered by large transformer models, vision language models and vision language action models — to run in real time at the edge while minimizing cloud dependency.
Optimized with the Jetson software stack to enable the low latency and high performance required in real-world applications, Jetson Thor supports all popular generative AI frameworks and AI reasoning models with unmatched real-time performance. These include Cosmos Reason, DeepSeek, Llama, Gemini and Qwen models, as well as domain-specific models for robotics like Isaac GR00T N1.5, enabling any developer to easily experiment and run inference locally.
NVIDIA Jetson Thor opens new capabilities for real-time reasoning with multi-sensor input. Further performance improvement is expected with FP4 and speculative decoding optimization.
With NVIDIA CUDA ecosystem support through its lifecycle, Jetson Thor is expected to deliver even better throughput and faster responses with future software releases.
Jetson Thor modules also run the full NVIDIA AI software stack to accelerate virtually every physical AI workflow with platforms including NVIDIA Isaac for robotics, NVIDIA Metropolis for video analytics AI agents and NVIDIA Holoscan for sensor processing.
With these software tools, developers can easily build and deploy applications, such as visual AI agents that can analyze live camera streams to monitor worker safety, humanoid robots capable of manipulation tasks in unstructured environments and smart operating rooms that guide surgeons based on data from multi-camera streams.
Jetson Thor Set to Advance Research Innovation
Research labs at Stanford University, Carnegie Mellon University and the University of Zurich are tapping Jetson Thor to push the boundaries of perception, planning and navigation models for a host of potential applications.
At Carnegie Mellon’s Robotics Institute, a research team uses NVIDIA Jetson to power autonomous robots that can navigate complex, unstructured environments to conduct medical triage as well as search and rescue.
“We can only do as much as the compute available allows,” said Sebastian Scherer, an associate research professor at the university and head of the AirLab. “Years ago, there was a big disconnect between computer vision and robotics because computer vision workloads were too slow for real-time decision-making — but now, models and computing have gotten fast enough so robots can handle much more nuanced tasks.”
Scherer anticipates that by upgrading from his team’s existing NVIDIA Jetson AGX Orin systems to Jetson AGX Thor developer kit, they’ll improve the performance of AI models including their award-winning MAC-VO model for robot perception at the edge, boost their sensor-fusion capabilities and be able to experiment with robot fleets.
Wield the Strength of Jetson Thor
The Jetson Thor family includes a developer kit and production modules. The developer kit includes a Jetson T5000 module, a reference carrier board with abundant connectivity, an active heatsink with a fan and a power supply.
NVIDIA Jetson AGX Thor Developer Kit
The Jetson ecosystem supports a variety of application requirements, high-speed industrial automation protocols and sensor interfaces, accelerating time to market for enterprise developers. Hardware partners including Advantech, Aetina, ConnectTech, MiiVii and TZTEK are building production-ready Jetson Thor systems with flexible I/O and custom configurations in various form factors.
Sensor and Actuator companies including Analog Devices, Inc., e-con Systems, Infineon, Leopard Imaging, RealSense and Sensing are using NVIDIA Holoscan Sensor Bridge — a platform that simplifies sensor fusion and data streaming — to connect sensor data from cameras, radar, lidar and more directly to GPU memory on Jetson Thor with ultralow latency.
Thousands of software companies can now elevate their traditional vision AI and robotics applications with multi-AI agent workflows running on Jetson Thor. Leading adopters include Openzeka, Rebotnix, Solomon and Vaidio.
More than 2 million developers use NVIDIA technologies to accelerate robotics workflows. Get started with Jetson Thor by reading the NVIDIA Technical Blog and watching the developer kit walkthrough.
To get hands-on experience with Jetson Thor, sign up to participate in upcoming hackathons with Seeed Studio and LeRobot by Hugging Face.
The NVIDIA Jetson AGX Thor developer kit is available now starting at NVIDIA Jetson T5000 modules are available starting at for 1,000 units. Buy now from authorized NVIDIA partners.
NVIDIA today also announced that the NVIDIA DRIVE AGX Thor developer kit, which provides a platform for developing autonomous vehicles and mobility solutions, is available for preorder. Deliveries are slated to start in September.
#nvidia #jetson #thor #unlocks #realtimeNVIDIA Jetson Thor Unlocks Real-Time Reasoning for General Robotics and Physical AIRobots around the world are about to get a lot smarter as physical AI developers plug in NVIDIA Jetson Thor modules — new robotics computers that can serve as the brains for robotic systems across research and industry. Robots demand rich sensor data and low-latency AI processing. Running real-time robotic applications requires significant AI compute and memory to handle concurrent data streams from multiple sensors. Jetson Thor, now in general availability, delivers 7.5x more AI compute, 3.1x more CPU performance and 2x more memory than its predecessor, the NVIDIA Jetson Orin, to make this possible on device. This performance leap will enable roboticists to process high-speed sensor data and perform visual reasoning at the edge — workflows that were previously too slow to run in dynamic real-world environments. This opens new possibilities for multimodal AI applications such as humanoid robotics. Agility Robotics, a leader in humanoid robotics, has integrated NVIDIA Jetson into the fifth generation of its robot, Digit — and plans to adopt Jetson Thor as the onboard compute platform for the sixth generation of Digit. This transition will enhance Digit’s real-time perception and decision-making capabilities, supporting increasingly complex AI skills and behaviors. Digit is commercially deployed and performs logistics tasks such as stacking, loading and palletizing in warehouse and manufacturing environments. “The powerful edge processing offered by Jetson Thor will take Digit to the next level — enhancing its real-time responsiveness and expanding its abilities to a broader, more complex set of skills,” said Peggy Johnson, CEO of Agility Robotics. “With Jetson Thor, we can deliver the latest physical AI advancements to optimize operations across our customers’ warehouses and factories.” Boston Dynamics — which has been building some of the industry’s most advanced robots for over 30 years — is integrating Jetson Thor into its humanoid robot Atlas, enabling Atlas to harness formerly server-level compute, AI workload acceleration, high-bandwidth data processing and significant memory on device. Beyond humanoids, Jetson Thor will accelerate various robotic applications — such as surgical assistants, smart tractors, delivery robots, industrial manipulators and visual AI agents — with real-time inference on device for larger, more complex AI models. A Giant Leap for Real-Time Robot Reasoning Jetson Thor is built for generative reasoning models. It enables the next generation of physical AI agents — powered by large transformer models, vision language models and vision language action models — to run in real time at the edge while minimizing cloud dependency. Optimized with the Jetson software stack to enable the low latency and high performance required in real-world applications, Jetson Thor supports all popular generative AI frameworks and AI reasoning models with unmatched real-time performance. These include Cosmos Reason, DeepSeek, Llama, Gemini and Qwen models, as well as domain-specific models for robotics like Isaac GR00T N1.5, enabling any developer to easily experiment and run inference locally. NVIDIA Jetson Thor opens new capabilities for real-time reasoning with multi-sensor input. Further performance improvement is expected with FP4 and speculative decoding optimization. With NVIDIA CUDA ecosystem support through its lifecycle, Jetson Thor is expected to deliver even better throughput and faster responses with future software releases. Jetson Thor modules also run the full NVIDIA AI software stack to accelerate virtually every physical AI workflow with platforms including NVIDIA Isaac for robotics, NVIDIA Metropolis for video analytics AI agents and NVIDIA Holoscan for sensor processing. With these software tools, developers can easily build and deploy applications, such as visual AI agents that can analyze live camera streams to monitor worker safety, humanoid robots capable of manipulation tasks in unstructured environments and smart operating rooms that guide surgeons based on data from multi-camera streams. Jetson Thor Set to Advance Research Innovation Research labs at Stanford University, Carnegie Mellon University and the University of Zurich are tapping Jetson Thor to push the boundaries of perception, planning and navigation models for a host of potential applications. At Carnegie Mellon’s Robotics Institute, a research team uses NVIDIA Jetson to power autonomous robots that can navigate complex, unstructured environments to conduct medical triage as well as search and rescue. “We can only do as much as the compute available allows,” said Sebastian Scherer, an associate research professor at the university and head of the AirLab. “Years ago, there was a big disconnect between computer vision and robotics because computer vision workloads were too slow for real-time decision-making — but now, models and computing have gotten fast enough so robots can handle much more nuanced tasks.” Scherer anticipates that by upgrading from his team’s existing NVIDIA Jetson AGX Orin systems to Jetson AGX Thor developer kit, they’ll improve the performance of AI models including their award-winning MAC-VO model for robot perception at the edge, boost their sensor-fusion capabilities and be able to experiment with robot fleets. Wield the Strength of Jetson Thor The Jetson Thor family includes a developer kit and production modules. The developer kit includes a Jetson T5000 module, a reference carrier board with abundant connectivity, an active heatsink with a fan and a power supply. NVIDIA Jetson AGX Thor Developer Kit The Jetson ecosystem supports a variety of application requirements, high-speed industrial automation protocols and sensor interfaces, accelerating time to market for enterprise developers. Hardware partners including Advantech, Aetina, ConnectTech, MiiVii and TZTEK are building production-ready Jetson Thor systems with flexible I/O and custom configurations in various form factors. Sensor and Actuator companies including Analog Devices, Inc., e-con Systems, Infineon, Leopard Imaging, RealSense and Sensing are using NVIDIA Holoscan Sensor Bridge — a platform that simplifies sensor fusion and data streaming — to connect sensor data from cameras, radar, lidar and more directly to GPU memory on Jetson Thor with ultralow latency. Thousands of software companies can now elevate their traditional vision AI and robotics applications with multi-AI agent workflows running on Jetson Thor. Leading adopters include Openzeka, Rebotnix, Solomon and Vaidio. More than 2 million developers use NVIDIA technologies to accelerate robotics workflows. Get started with Jetson Thor by reading the NVIDIA Technical Blog and watching the developer kit walkthrough. To get hands-on experience with Jetson Thor, sign up to participate in upcoming hackathons with Seeed Studio and LeRobot by Hugging Face. The NVIDIA Jetson AGX Thor developer kit is available now starting at NVIDIA Jetson T5000 modules are available starting at for 1,000 units. Buy now from authorized NVIDIA partners. NVIDIA today also announced that the NVIDIA DRIVE AGX Thor developer kit, which provides a platform for developing autonomous vehicles and mobility solutions, is available for preorder. Deliveries are slated to start in September. #nvidia #jetson #thor #unlocks #realtime· 2 Comments ·0 Shares
797
-
Hot Topics at Hot Chips: Inference, Networking, AI Innovation at Every Scale — All Built on NVIDIA
AI reasoning, inference and networking will be top of mind for attendees of next week’s Hot Chips conference.
A key forum for processor and system architects from industry and academia, Hot Chips — running Aug. 24-26 at Stanford University — showcases the latest innovations poised to advance AI factories and drive revenue for the trillion-dollar data center computing market.
At the conference, NVIDIA will join industry leaders including Google and Microsoft in a “tutorial” session — taking place on Sunday, Aug. 24 — that discusses designing rack-scale architecture for data centers.
In addition, NVIDIA experts will present at four sessions and one tutorial detailing how:
NVIDIA networking, including the NVIDIA ConnectX-8 SuperNIC, delivers AI reasoning at rack- and data-center scale.Neural rendering advancements and massive leaps in inference — powered by the NVIDIA Blackwell architecture, including the NVIDIA GeForce RTX 5090 GPU — provide next-level graphics and simulation capabilities.Co-packaged opticsswitches with integrated silicon photonics — built with light-speed fiber rather than copper wiring to send information quicker and using less power — enable efficient, high-performance, gigawatt-scale AI factories. The talk will also highlight NVIDIA Spectrum-XGS Ethernet, a new scale-across technology for unifying distributed data centers into AI super-factories.The NVIDIA GB10 Superchip serves as the engine within the NVIDIA DGX Spark desktop supercomputer.It’s all part of how NVIDIA’s latest technologies are accelerating inference to drive AI innovation everywhere, at every scale.
NVIDIA Networking Fosters AI Innovation at Scale
AI reasoning — when artificial intelligence systems can analyze and solve complex problems through multiple AI inference passes — requires rack-scale performance to deliver optimal user experiences efficiently.
In data centers powering today’s AI workloads, networking acts as the central nervous system, connecting all the components — servers, storage devices and other hardware — into a single, cohesive, powerful computing unit.
NVIDIA ConnectX-8 SuperNIC
Burstein’s Hot Chips session will dive into how NVIDIA networking technologies — particularly NVIDIA ConnectX-8 SuperNICs — enable high-speed, low-latency, multi-GPU communication to deliver market-leading AI reasoning performance at scale.
As part of the NVIDIA networking platform, NVIDIA NVLink, NVLink Switch and NVLink Fusion deliver scale-up connectivity — linking GPUs and compute elements within and across servers for ultra low-latency, high-bandwidth data exchange.
NVIDIA Spectrum-X Ethernet provides the scale-out fabric to connect entire clusters, rapidly streaming massive datasets into AI models and orchestrating GPU-to-GPU communication across the data center. Spectrum-XGS Ethernet scale-across technology extends the extreme performance and scale of Spectrum-X Ethernet to interconnect multiple, distributed data centers to form AI super-factories capable of giga-scale intelligence.
Connecting distributed AI data centers with NVIDIA Spectrum-XGS Ethernet.
At the heart of Spectrum-X Ethernet, CPO switches push the limits of performance and efficiency for AI infrastructure at scale, and will be covered in detail by Shainer in his talk.
NVIDIA GB200 NVL72 — an exascale computer in a single rack — features 36 NVIDIA GB200 Superchips, each containing two NVIDIA B200 GPUs and an NVIDIA Grace CPU, interconnected by the largest NVLink domain ever offered, with NVLink Switch providing 130 terabytes per second of low-latency GPU communications for AI and high-performance computing workloads.
An NVIDIA rack-scale system.
Built with the NVIDIA Blackwell architecture, GB200 NVL72 systems deliver massive leaps in reasoning inference performance.
NVIDIA Blackwell and CUDA Bring AI to Millions of Developers
The NVIDIA GeForce RTX 5090 GPU — also powered by Blackwell and to be covered in Blackstein’s talk — doubles performance in today’s games with NVIDIA DLSS 4 technology.
NVIDIA GeForce RTX 5090 GPU
It can also add neural rendering features for games to deliver up to 10x performance, 10x footprint amplification and a 10x reduction in design cycles, helping enhance realism in computer graphics and simulation. This offers smooth, responsive visual experiences at low energy consumption and improves the lifelike simulation of characters and effects.
NVIDIA CUDA, the world’s most widely available computing infrastructure, lets users deploy and run AI models using NVIDIA Blackwell anywhere.
Hundreds of millions of GPUs run CUDA across the globe, from NVIDIA GB200 NVL72 rack-scale systems to GeForce RTX– and NVIDIA RTX PRO-powered PCs and workstations, with NVIDIA DGX Spark powered by NVIDIA GB10 — discussed in Skende’s session — coming soon.
From Algorithms to AI Supercomputers — Optimized for LLMs
NVIDIA DGX Spark
Delivering powerful performance and capabilities in a compact package, DGX Spark lets developers, researchers, data scientists and students push the boundaries of generative AI right at their desktops, and accelerate workloads across industries.
As part of the NVIDIA Blackwell platform, DGX Spark brings support for NVFP4, a low-precision numerical format to enable efficient agentic AI inference, particularly of large language models. Learn more about NVFP4 in this NVIDIA Technical Blog.
Open-Source Collaborations Propel Inference Innovation
NVIDIA accelerates several open-source libraries and frameworks to accelerate and optimize AI workloads for LLMs and distributed inference. These include NVIDIA TensorRT-LLM, NVIDIA Dynamo, TileIR, Cutlass, the NVIDIA Collective Communication Library and NIX — which are integrated into millions of workflows.
Allowing developers to build with their framework of choice, NVIDIA has collaborated with top open framework providers to offer model optimizations for FlashInfer, PyTorch, SGLang, vLLM and others.
Plus, NVIDIA NIM microservices are available for popular open models like OpenAI’s gpt-oss and Llama 4, making it easy for developers to operate managed application programming interfaces with the flexibility and security of self-hosting models on their preferred infrastructure.
Learn more about the latest advancements in inference and accelerated computing by joining NVIDIA at Hot Chips.
#hot #topics #chips #inference #networkingHot Topics at Hot Chips: Inference, Networking, AI Innovation at Every Scale — All Built on NVIDIAAI reasoning, inference and networking will be top of mind for attendees of next week’s Hot Chips conference. A key forum for processor and system architects from industry and academia, Hot Chips — running Aug. 24-26 at Stanford University — showcases the latest innovations poised to advance AI factories and drive revenue for the trillion-dollar data center computing market. At the conference, NVIDIA will join industry leaders including Google and Microsoft in a “tutorial” session — taking place on Sunday, Aug. 24 — that discusses designing rack-scale architecture for data centers. In addition, NVIDIA experts will present at four sessions and one tutorial detailing how: NVIDIA networking, including the NVIDIA ConnectX-8 SuperNIC, delivers AI reasoning at rack- and data-center scale.Neural rendering advancements and massive leaps in inference — powered by the NVIDIA Blackwell architecture, including the NVIDIA GeForce RTX 5090 GPU — provide next-level graphics and simulation capabilities.Co-packaged opticsswitches with integrated silicon photonics — built with light-speed fiber rather than copper wiring to send information quicker and using less power — enable efficient, high-performance, gigawatt-scale AI factories. The talk will also highlight NVIDIA Spectrum-XGS Ethernet, a new scale-across technology for unifying distributed data centers into AI super-factories.The NVIDIA GB10 Superchip serves as the engine within the NVIDIA DGX Spark desktop supercomputer.It’s all part of how NVIDIA’s latest technologies are accelerating inference to drive AI innovation everywhere, at every scale. NVIDIA Networking Fosters AI Innovation at Scale AI reasoning — when artificial intelligence systems can analyze and solve complex problems through multiple AI inference passes — requires rack-scale performance to deliver optimal user experiences efficiently. In data centers powering today’s AI workloads, networking acts as the central nervous system, connecting all the components — servers, storage devices and other hardware — into a single, cohesive, powerful computing unit. NVIDIA ConnectX-8 SuperNIC Burstein’s Hot Chips session will dive into how NVIDIA networking technologies — particularly NVIDIA ConnectX-8 SuperNICs — enable high-speed, low-latency, multi-GPU communication to deliver market-leading AI reasoning performance at scale. As part of the NVIDIA networking platform, NVIDIA NVLink, NVLink Switch and NVLink Fusion deliver scale-up connectivity — linking GPUs and compute elements within and across servers for ultra low-latency, high-bandwidth data exchange. NVIDIA Spectrum-X Ethernet provides the scale-out fabric to connect entire clusters, rapidly streaming massive datasets into AI models and orchestrating GPU-to-GPU communication across the data center. Spectrum-XGS Ethernet scale-across technology extends the extreme performance and scale of Spectrum-X Ethernet to interconnect multiple, distributed data centers to form AI super-factories capable of giga-scale intelligence. Connecting distributed AI data centers with NVIDIA Spectrum-XGS Ethernet. At the heart of Spectrum-X Ethernet, CPO switches push the limits of performance and efficiency for AI infrastructure at scale, and will be covered in detail by Shainer in his talk. NVIDIA GB200 NVL72 — an exascale computer in a single rack — features 36 NVIDIA GB200 Superchips, each containing two NVIDIA B200 GPUs and an NVIDIA Grace CPU, interconnected by the largest NVLink domain ever offered, with NVLink Switch providing 130 terabytes per second of low-latency GPU communications for AI and high-performance computing workloads. An NVIDIA rack-scale system. Built with the NVIDIA Blackwell architecture, GB200 NVL72 systems deliver massive leaps in reasoning inference performance. NVIDIA Blackwell and CUDA Bring AI to Millions of Developers The NVIDIA GeForce RTX 5090 GPU — also powered by Blackwell and to be covered in Blackstein’s talk — doubles performance in today’s games with NVIDIA DLSS 4 technology. NVIDIA GeForce RTX 5090 GPU It can also add neural rendering features for games to deliver up to 10x performance, 10x footprint amplification and a 10x reduction in design cycles, helping enhance realism in computer graphics and simulation. This offers smooth, responsive visual experiences at low energy consumption and improves the lifelike simulation of characters and effects. NVIDIA CUDA, the world’s most widely available computing infrastructure, lets users deploy and run AI models using NVIDIA Blackwell anywhere. Hundreds of millions of GPUs run CUDA across the globe, from NVIDIA GB200 NVL72 rack-scale systems to GeForce RTX– and NVIDIA RTX PRO-powered PCs and workstations, with NVIDIA DGX Spark powered by NVIDIA GB10 — discussed in Skende’s session — coming soon. From Algorithms to AI Supercomputers — Optimized for LLMs NVIDIA DGX Spark Delivering powerful performance and capabilities in a compact package, DGX Spark lets developers, researchers, data scientists and students push the boundaries of generative AI right at their desktops, and accelerate workloads across industries. As part of the NVIDIA Blackwell platform, DGX Spark brings support for NVFP4, a low-precision numerical format to enable efficient agentic AI inference, particularly of large language models. Learn more about NVFP4 in this NVIDIA Technical Blog. Open-Source Collaborations Propel Inference Innovation NVIDIA accelerates several open-source libraries and frameworks to accelerate and optimize AI workloads for LLMs and distributed inference. These include NVIDIA TensorRT-LLM, NVIDIA Dynamo, TileIR, Cutlass, the NVIDIA Collective Communication Library and NIX — which are integrated into millions of workflows. Allowing developers to build with their framework of choice, NVIDIA has collaborated with top open framework providers to offer model optimizations for FlashInfer, PyTorch, SGLang, vLLM and others. Plus, NVIDIA NIM microservices are available for popular open models like OpenAI’s gpt-oss and Llama 4, making it easy for developers to operate managed application programming interfaces with the flexibility and security of self-hosting models on their preferred infrastructure. Learn more about the latest advancements in inference and accelerated computing by joining NVIDIA at Hot Chips. #hot #topics #chips #inference #networking· 2 Comments ·0 Shares
332
-
RIKEN, Japan’s Leading Science Institute, Taps Fujitsu and NVIDIA for Next Flagship Supercomputer
Japan is once again building a landmark high-performance computing system — not simply by chasing speed, but by rethinking how technology can best serve the nation’s most urgent scientific needs.
At the FugakuNEXT International Initiative Launch Ceremony held in Tokyo on Aug. 22, leaders from RIKEN, Japan’s top research institute, announced the start of an international collaboration with Fujitsu and NVIDIA to co-design FugakuNEXT, the successor to the world-renowned supercomputer, Fugaku.
Awarded early in the process, the contract enables the partners to work side by side in shaping the system’s architecture to address Japan’s most critical research priorities — from earth systems modeling and disaster resilience to drug discovery and advanced manufacturing.
More than an upgrade, the effort will highlight Japan’s embrace of modern AI and showcase Japanese innovations that can be harnessed by researchers and enterprises across the globe.
The ceremony featured remarks from the initiative’s leaders, RIKEN President Makoto Gonokami and Satoshi Matsuoka, director of the RIKEN Center for Computational Science and one of Japan’s most respected high-performance computing architects.
Fujitsu Chief Technology Officer Vivek Mahajan attended, emphasizing the company’s role in advancing Japan’s computing capabilities.
Ian Buck, vice president of hyperscale and high-performance computing at NVIDIA, attended in person as well to discuss the collaborative design approach and how the resulting platform will serve as a foundation for innovation well into the next decade.
Momentum has been building. When NVIDIA founder and CEO Jensen Huang touched down in Tokyo last year, he called on Japan to seize the moment — to put NVIDIA’s latest technologies to work building its own AI, on its own soil, with its own infrastructure.
FugakuNEXT answers that call, drawing on NVIDIA’s whole software stack — from NVIDIA CUDA-X libraries such as NVIDIA cuQuantum for quantum simulation, RAPIDS for data science, NVIDIA TensorRT for high-performance inference and NVIDIA NeMo for large language model development, to other domain-specific software development kits tailored for science and industry.
Innovations pioneered on FugakuNEXT could become blueprints for the world.
What’s Inside
FugakuNEXT will be a hybrid AI-HPC system, combining simulation and AI workloads.
It will feature FUJITSU-MONAKA-X CPUs, which can be paired with NVIDIA technologies using NVLink Fusion, new silicon enabling high-bandwidth connections between Fujitsu’s CPUs and NVIDIA’s architecture.
The system will be built for speed, scale and efficiency.
What It Will Do
FugakuNEXT will support a wide range of applications — such as automating hypothesis generation, code creation and experiment simulation.
Scientific research: Accelerating simulations with surrogate models and physics-informed neural networks.
Manufacturing: Using AI to learn from simulations to generate efficient and aesthetically pleasing designs faster than ever before.
Earth systems modeling: aiding disaster preparedness and prediction for earthquakes and severe weather, and more.
RIKEN, Fujitsu and NVIDIA will collaborate on software developments, including tools for mixed-precision computing, continuous benchmarking, and performance optimization.
FugakuNEXT isn’t just a technical upgrade — it’s a strategic investment in Japan’s future.
Backed by Japan’s MEXT, it will serve universities, government agencies, and industry partners nationwide.
It marks the start of a new era in Japanese supercomputing — one built on sovereign infrastructure, global collaboration, and a commitment to scientific leadership.
Image courtesy of RIKEN
#riken #japans #leading #science #instituteRIKEN, Japan’s Leading Science Institute, Taps Fujitsu and NVIDIA for Next Flagship SupercomputerJapan is once again building a landmark high-performance computing system — not simply by chasing speed, but by rethinking how technology can best serve the nation’s most urgent scientific needs. At the FugakuNEXT International Initiative Launch Ceremony held in Tokyo on Aug. 22, leaders from RIKEN, Japan’s top research institute, announced the start of an international collaboration with Fujitsu and NVIDIA to co-design FugakuNEXT, the successor to the world-renowned supercomputer, Fugaku. Awarded early in the process, the contract enables the partners to work side by side in shaping the system’s architecture to address Japan’s most critical research priorities — from earth systems modeling and disaster resilience to drug discovery and advanced manufacturing. More than an upgrade, the effort will highlight Japan’s embrace of modern AI and showcase Japanese innovations that can be harnessed by researchers and enterprises across the globe. The ceremony featured remarks from the initiative’s leaders, RIKEN President Makoto Gonokami and Satoshi Matsuoka, director of the RIKEN Center for Computational Science and one of Japan’s most respected high-performance computing architects. Fujitsu Chief Technology Officer Vivek Mahajan attended, emphasizing the company’s role in advancing Japan’s computing capabilities. Ian Buck, vice president of hyperscale and high-performance computing at NVIDIA, attended in person as well to discuss the collaborative design approach and how the resulting platform will serve as a foundation for innovation well into the next decade. Momentum has been building. When NVIDIA founder and CEO Jensen Huang touched down in Tokyo last year, he called on Japan to seize the moment — to put NVIDIA’s latest technologies to work building its own AI, on its own soil, with its own infrastructure. FugakuNEXT answers that call, drawing on NVIDIA’s whole software stack — from NVIDIA CUDA-X libraries such as NVIDIA cuQuantum for quantum simulation, RAPIDS for data science, NVIDIA TensorRT for high-performance inference and NVIDIA NeMo for large language model development, to other domain-specific software development kits tailored for science and industry. Innovations pioneered on FugakuNEXT could become blueprints for the world. What’s Inside FugakuNEXT will be a hybrid AI-HPC system, combining simulation and AI workloads. It will feature FUJITSU-MONAKA-X CPUs, which can be paired with NVIDIA technologies using NVLink Fusion, new silicon enabling high-bandwidth connections between Fujitsu’s CPUs and NVIDIA’s architecture. The system will be built for speed, scale and efficiency. What It Will Do FugakuNEXT will support a wide range of applications — such as automating hypothesis generation, code creation and experiment simulation. Scientific research: Accelerating simulations with surrogate models and physics-informed neural networks. Manufacturing: Using AI to learn from simulations to generate efficient and aesthetically pleasing designs faster than ever before. Earth systems modeling: aiding disaster preparedness and prediction for earthquakes and severe weather, and more. RIKEN, Fujitsu and NVIDIA will collaborate on software developments, including tools for mixed-precision computing, continuous benchmarking, and performance optimization. FugakuNEXT isn’t just a technical upgrade — it’s a strategic investment in Japan’s future. Backed by Japan’s MEXT, it will serve universities, government agencies, and industry partners nationwide. It marks the start of a new era in Japanese supercomputing — one built on sovereign infrastructure, global collaboration, and a commitment to scientific leadership. Image courtesy of RIKEN #riken #japans #leading #science #institute2 Comments ·0 Shares -
Gearing Up for the Gigawatt Data Center Age
Across the globe, AI factories are rising — massive new data centers built not to serve up web pages or email, but to train and deploy intelligence itself. Internet giants have invested billions in cloud-scale AI infrastructure for their customers. Companies are racing to build AI foundries that will spawn the next generation of products and services. Governments are investing too, eager to harness AI for personalized medicine and language services tailored to national populations.
Welcome to the age of AI factories — where the rules are being rewritten and the wiring doesn’t look anything like the old internet. These aren’t typical hyperscale data centers. They’re something else entirely. Think of them as high-performance engines stitched together from tens to hundreds of thousands of GPUs — not just built, but orchestrated, operated and activated as a single unit. And that orchestration? It’s the whole game.
This giant data center has become the new unit of computing, and the way these GPUs are connected defines what this unit of computing can do. One network architecture won’t cut it. What’s needed is a layered design with bleeding-edge technologies — like co-packaged optics that once seemed like science fiction.
The complexity isn’t a bug; it’s the defining feature. AI infrastructure is diverging fast from everything that came before it, and if there isn’t rethinking on how the pipes connect, scale breaks down. Get the network layers wrong, and the whole machine grinds to a halt. Get it right, and gain extraordinary performance.
With that shift comes weight — literally. A decade ago, chips were built to be sleek and lightweight. Now, the cutting edge looks like the multi‑hundred‑pound copper spine of a server rack. Liquid-cooled manifolds. Custom busbars. Copper spines. AI now demands massive, industrial-scale hardware. And the deeper the models go, the more these machines scale up, and out.
The NVIDIA NVLink spine, for example, is built from over 5,000 coaxial cables — tightly wound and precisely routed. It moves more data per second than the entire internet. That’s 130 TB/s of GPU-to-GPU bandwidth, fully meshed.
This isn’t just fast. It’s foundational. The AI super-highway now lives inside the rack.
The Data Center Is the Computer
Training the modern large language modelsbehind AI isn’t about burning cycles on a single machine. It’s about orchestrating the work of tens or even hundreds of thousands of GPUs that are the heavy lifters of AI computation.
These systems rely on distributed computing, splitting massive calculations across nodes, where each node handles a slice of the workload. In training, those slices — typically massive matrices of numbers — need to be regularly merged and updated. That merging occurs through collective operations, such as “all-reduce”and “all-to-all”.
These processes are susceptible to the speed and responsiveness of the network — what engineers call latencyand bandwidth— causing stalls in training.
For inference — the process of running trained models to generate answers or predictions — the challenges flip. Retrieval-augmented generation systems, which combine LLMs with search, demand real-time lookups and responses. And in cloud environments, multi-tenant inference means keeping workloads from different customers running smoothly, without interference. That requires lightning-fast, high-throughput networking that can handle massive demand with strict isolation between users.
Traditional Ethernet was designed for single-server workloads — not for the demands of distributed AI. Tolerating jitter and inconsistent delivery were once acceptable. Now, it’s a bottleneck. Traditional Ethernet switch architectures were never designed for consistent, predictable performance — and that legacy still shapes their latest generations.
Distributed computing requires a scale-out infrastructure built for zero-jitter operation — one that can handle bursts of extreme throughput, deliver low latency, maintain predictable and consistent RDMA performance, and isolate network noise. This is why InfiniBand networking is the gold standard for high-performance computing supercomputers and AI factories.
With NVIDIA Quantum InfiniBand, collective operations run inside the network itself using Scalable Hierarchical Aggregation and Reduction Protocol technology, doubling data bandwidth for reductions. It uses adaptive routing and telemetry-based congestion control to spread flows across paths, guarantee deterministic bandwidth and isolate noise. These optimizations let InfiniBand scale AI communication with precision. It’s why NVIDIA Quantum infrastructure connects the majority of the systems on the TOP500 list of the world’s most powerful supercomputers, demonstrating 35% growth in just two years.
For clusters spanning dozens of racks, NVIDIA Quantum‑X800 Infiniband switches push InfiniBand to new heights. Each switch provides 144 ports of 800 Gbps connectivity, featuring hardware-based SHARPv4, adaptive routing and telemetry-based congestion control. The platform integrates co‑packaged silicon photonics to minimize the distance between electronics and optics, reducing power consumption and latency. Paired with NVIDIA ConnectX-8 SuperNICs delivering 800 Gb/s per GPU, this fabric links trillion-parameter models and drives in-network compute.
But hyperscalers and enterprises have invested billions in their Ethernet software infrastructure. They need a quick path forward that uses the existing ecosystem for AI workloads. Enter NVIDIA Spectrum‑X: a new kind of Ethernet purpose-built for distributed AI.
Spectrum‑X Ethernet: Bringing AI to the Enterprise
Spectrum‑X reimagines Ethernet for AI. Launched in 2023 Spectrum‑X delivers lossless networking, adaptive routing and performance isolation. The SN5610 switch, based on the Spectrum‑4 ASIC, supports port speeds up to 800 Gb/s and uses NVIDIA’s congestion control to maintain 95% data throughput at scale.
Spectrum‑X is fully standards‑based Ethernet. In addition to supporting Cumulus Linux, it supports the open‑source SONiC network operating system — giving customers flexibility. A key ingredient is NVIDIA SuperNICs — based on NVIDIA BlueField-3 or ConnectX-8 — which provide up to 800 Gb/s RoCE connectivity and offload packet reordering and congestion management.
Spectrum-X brings InfiniBand’s best innovations — like telemetry-driven congestion control, adaptive load balancing and direct data placement — to Ethernet, enabling enterprises to scale to hundreds of thousands of GPUs. Large-scale systems with Spectrum‑X, including the world’s most colossal AI supercomputer, have achieved 95% data throughput with zero application latency degradation. Standard Ethernet fabrics would deliver only ~60% throughput due to flow collisions.
A Portfolio for Scale‑Up and Scale‑Out
No single network can serve every layer of an AI factory. NVIDIA’s approach is to match the right fabric to the right tier, then tie everything together with software and silicon.
NVLink: Scale Up Inside the Rack
Inside a server rack, GPUs need to talk to each other as if they were different cores on the same chip. NVIDIA NVLink and NVLink Switch extend GPU memory and bandwidth across nodes. In an NVIDIA GB300 NVL72 system, 36 NVIDIA Grace CPUs and 72 NVIDIA Blackwell Ultra GPUs are connected in a single NVLink domain, with an aggregate bandwidth of 130 TB/s. NVLink Switch technology further extends this fabric: a single GB300 NVL72 system can offer 130 TB/s of GPU bandwidth, enabling clusters to support 9x the GPU count of a single 8‑GPU server. With NVLink, the entire rack becomes one large GPU.
Photonics: The Next Leap
To reach million‑GPU AI factories, the network must break the power and density limits of pluggable optics. NVIDIA Quantum-X and Spectrum-X Photonics switches integrate silicon photonics directly into the switch package, delivering 128 to 512 ports of 800 Gb/s with total bandwidths ranging from 100 Tb/s to 400 Tb/s. These switches offer 3.5x more power efficiency and 10x better resiliency compared with traditional optics, paving the way for gigawatt‑scale AI factories.
Delivering on the Promise of Open Standards
Spectrum‑X and NVIDIA Quantum InfiniBand are built on open standards. Spectrum‑X is fully standards‑based Ethernet with support for open Ethernet stacks like SONiC, while NVIDIA Quantum InfiniBand and Spectrum-X conform to the InfiniBand Trade Association’s InfiniBand and RDMA over Converged Ethernetspecifications. Key elements of NVIDIA’s software stack — including NCCL and DOCA libraries — run on a variety of hardware, and partners such as Cisco, Dell Technologies, HPE and Supermicro integrate Spectrum-X into their systems.
Open standards create the foundation for interoperability, but real-world AI clusters require tight optimization across the entire stack — GPUs, NICs, switches, cables and software. Vendors that invest in end‑to‑end integration deliver better latency and throughput. SONiC, the open‑source network operating system hardened in hyperscale data centers, eliminates licensing and vendor lock‑in and allows intense customization, but operators still choose purpose‑built hardware and software bundles to meet AI’s performance needs. In practice, open standards alone don’t deliver deterministic performance; they need innovation layered on top.
Toward Million‑GPU AI Factories
AI factories are scaling fast. Governments in Europe are building seven national AI factories, while cloud providers and enterprises across Japan, India and Norway are rolling out NVIDIA‑powered AI infrastructure. The next horizon is gigawatt‑class facilities with a million GPUs. To get there, the network must evolve from an afterthought to a pillar of AI infrastructure.
The lesson from the gigawatt data center age is simple: the data center is now the computer. NVLink stitches together GPUs inside the rack. NVIDIA Quantum InfiniBand scales them across it. Spectrum-X brings that performance to broader markets. Silicon photonics makes it sustainable. Everything is open where it matters, optimized where it counts.
#gearing #gigawatt #data #center #ageGearing Up for the Gigawatt Data Center AgeAcross the globe, AI factories are rising — massive new data centers built not to serve up web pages or email, but to train and deploy intelligence itself. Internet giants have invested billions in cloud-scale AI infrastructure for their customers. Companies are racing to build AI foundries that will spawn the next generation of products and services. Governments are investing too, eager to harness AI for personalized medicine and language services tailored to national populations. Welcome to the age of AI factories — where the rules are being rewritten and the wiring doesn’t look anything like the old internet. These aren’t typical hyperscale data centers. They’re something else entirely. Think of them as high-performance engines stitched together from tens to hundreds of thousands of GPUs — not just built, but orchestrated, operated and activated as a single unit. And that orchestration? It’s the whole game. This giant data center has become the new unit of computing, and the way these GPUs are connected defines what this unit of computing can do. One network architecture won’t cut it. What’s needed is a layered design with bleeding-edge technologies — like co-packaged optics that once seemed like science fiction. The complexity isn’t a bug; it’s the defining feature. AI infrastructure is diverging fast from everything that came before it, and if there isn’t rethinking on how the pipes connect, scale breaks down. Get the network layers wrong, and the whole machine grinds to a halt. Get it right, and gain extraordinary performance. With that shift comes weight — literally. A decade ago, chips were built to be sleek and lightweight. Now, the cutting edge looks like the multi‑hundred‑pound copper spine of a server rack. Liquid-cooled manifolds. Custom busbars. Copper spines. AI now demands massive, industrial-scale hardware. And the deeper the models go, the more these machines scale up, and out. The NVIDIA NVLink spine, for example, is built from over 5,000 coaxial cables — tightly wound and precisely routed. It moves more data per second than the entire internet. That’s 130 TB/s of GPU-to-GPU bandwidth, fully meshed. This isn’t just fast. It’s foundational. The AI super-highway now lives inside the rack. The Data Center Is the Computer Training the modern large language modelsbehind AI isn’t about burning cycles on a single machine. It’s about orchestrating the work of tens or even hundreds of thousands of GPUs that are the heavy lifters of AI computation. These systems rely on distributed computing, splitting massive calculations across nodes, where each node handles a slice of the workload. In training, those slices — typically massive matrices of numbers — need to be regularly merged and updated. That merging occurs through collective operations, such as “all-reduce”and “all-to-all”. These processes are susceptible to the speed and responsiveness of the network — what engineers call latencyand bandwidth— causing stalls in training. For inference — the process of running trained models to generate answers or predictions — the challenges flip. Retrieval-augmented generation systems, which combine LLMs with search, demand real-time lookups and responses. And in cloud environments, multi-tenant inference means keeping workloads from different customers running smoothly, without interference. That requires lightning-fast, high-throughput networking that can handle massive demand with strict isolation between users. Traditional Ethernet was designed for single-server workloads — not for the demands of distributed AI. Tolerating jitter and inconsistent delivery were once acceptable. Now, it’s a bottleneck. Traditional Ethernet switch architectures were never designed for consistent, predictable performance — and that legacy still shapes their latest generations. Distributed computing requires a scale-out infrastructure built for zero-jitter operation — one that can handle bursts of extreme throughput, deliver low latency, maintain predictable and consistent RDMA performance, and isolate network noise. This is why InfiniBand networking is the gold standard for high-performance computing supercomputers and AI factories. With NVIDIA Quantum InfiniBand, collective operations run inside the network itself using Scalable Hierarchical Aggregation and Reduction Protocol technology, doubling data bandwidth for reductions. It uses adaptive routing and telemetry-based congestion control to spread flows across paths, guarantee deterministic bandwidth and isolate noise. These optimizations let InfiniBand scale AI communication with precision. It’s why NVIDIA Quantum infrastructure connects the majority of the systems on the TOP500 list of the world’s most powerful supercomputers, demonstrating 35% growth in just two years. For clusters spanning dozens of racks, NVIDIA Quantum‑X800 Infiniband switches push InfiniBand to new heights. Each switch provides 144 ports of 800 Gbps connectivity, featuring hardware-based SHARPv4, adaptive routing and telemetry-based congestion control. The platform integrates co‑packaged silicon photonics to minimize the distance between electronics and optics, reducing power consumption and latency. Paired with NVIDIA ConnectX-8 SuperNICs delivering 800 Gb/s per GPU, this fabric links trillion-parameter models and drives in-network compute. But hyperscalers and enterprises have invested billions in their Ethernet software infrastructure. They need a quick path forward that uses the existing ecosystem for AI workloads. Enter NVIDIA Spectrum‑X: a new kind of Ethernet purpose-built for distributed AI. Spectrum‑X Ethernet: Bringing AI to the Enterprise Spectrum‑X reimagines Ethernet for AI. Launched in 2023 Spectrum‑X delivers lossless networking, adaptive routing and performance isolation. The SN5610 switch, based on the Spectrum‑4 ASIC, supports port speeds up to 800 Gb/s and uses NVIDIA’s congestion control to maintain 95% data throughput at scale. Spectrum‑X is fully standards‑based Ethernet. In addition to supporting Cumulus Linux, it supports the open‑source SONiC network operating system — giving customers flexibility. A key ingredient is NVIDIA SuperNICs — based on NVIDIA BlueField-3 or ConnectX-8 — which provide up to 800 Gb/s RoCE connectivity and offload packet reordering and congestion management. Spectrum-X brings InfiniBand’s best innovations — like telemetry-driven congestion control, adaptive load balancing and direct data placement — to Ethernet, enabling enterprises to scale to hundreds of thousands of GPUs. Large-scale systems with Spectrum‑X, including the world’s most colossal AI supercomputer, have achieved 95% data throughput with zero application latency degradation. Standard Ethernet fabrics would deliver only ~60% throughput due to flow collisions. A Portfolio for Scale‑Up and Scale‑Out No single network can serve every layer of an AI factory. NVIDIA’s approach is to match the right fabric to the right tier, then tie everything together with software and silicon. NVLink: Scale Up Inside the Rack Inside a server rack, GPUs need to talk to each other as if they were different cores on the same chip. NVIDIA NVLink and NVLink Switch extend GPU memory and bandwidth across nodes. In an NVIDIA GB300 NVL72 system, 36 NVIDIA Grace CPUs and 72 NVIDIA Blackwell Ultra GPUs are connected in a single NVLink domain, with an aggregate bandwidth of 130 TB/s. NVLink Switch technology further extends this fabric: a single GB300 NVL72 system can offer 130 TB/s of GPU bandwidth, enabling clusters to support 9x the GPU count of a single 8‑GPU server. With NVLink, the entire rack becomes one large GPU. Photonics: The Next Leap To reach million‑GPU AI factories, the network must break the power and density limits of pluggable optics. NVIDIA Quantum-X and Spectrum-X Photonics switches integrate silicon photonics directly into the switch package, delivering 128 to 512 ports of 800 Gb/s with total bandwidths ranging from 100 Tb/s to 400 Tb/s. These switches offer 3.5x more power efficiency and 10x better resiliency compared with traditional optics, paving the way for gigawatt‑scale AI factories. Delivering on the Promise of Open Standards Spectrum‑X and NVIDIA Quantum InfiniBand are built on open standards. Spectrum‑X is fully standards‑based Ethernet with support for open Ethernet stacks like SONiC, while NVIDIA Quantum InfiniBand and Spectrum-X conform to the InfiniBand Trade Association’s InfiniBand and RDMA over Converged Ethernetspecifications. Key elements of NVIDIA’s software stack — including NCCL and DOCA libraries — run on a variety of hardware, and partners such as Cisco, Dell Technologies, HPE and Supermicro integrate Spectrum-X into their systems. Open standards create the foundation for interoperability, but real-world AI clusters require tight optimization across the entire stack — GPUs, NICs, switches, cables and software. Vendors that invest in end‑to‑end integration deliver better latency and throughput. SONiC, the open‑source network operating system hardened in hyperscale data centers, eliminates licensing and vendor lock‑in and allows intense customization, but operators still choose purpose‑built hardware and software bundles to meet AI’s performance needs. In practice, open standards alone don’t deliver deterministic performance; they need innovation layered on top. Toward Million‑GPU AI Factories AI factories are scaling fast. Governments in Europe are building seven national AI factories, while cloud providers and enterprises across Japan, India and Norway are rolling out NVIDIA‑powered AI infrastructure. The next horizon is gigawatt‑class facilities with a million GPUs. To get there, the network must evolve from an afterthought to a pillar of AI infrastructure. The lesson from the gigawatt data center age is simple: the data center is now the computer. NVLink stitches together GPUs inside the rack. NVIDIA Quantum InfiniBand scales them across it. Spectrum-X brings that performance to broader markets. Silicon photonics makes it sustainable. Everything is open where it matters, optimized where it counts. #gearing #gigawatt #data #center #age2 Comments ·0 Shares -
New Lightweight AI Model for Project G-Assist Brings Support for 6GB NVIDIA GeForce RTX and RTX PRO GPUs
At Gamescom, NVIDIA is releasing its first major update to Project G‑Assist — an experimental on-device AI assistant that allows users to tune their NVIDIA RTX systems with voice and text commands.
The update brings a new AI model that uses 40% less VRAM, improves tool-calling intelligence and extends G-Assist support to all RTX GPUs with 6GB or more VRAM, including laptops. Plus, a new G-Assist Plug-In Hub enables users to easily discover and download plug-ins to enable more G-Assist features.
NVIDIA also announced a new path-traced particle system, coming in September to the NVIDIA RTX Remix modding platform, that brings fully simulated physics, dynamic shadows and realistic reflections to visual effects.
In addition, NVIDIA named the winners of the NVIDIA and ModDB RTX Remix Mod Contest. Check out the winners and finalist RTX mods in the RTX Remix GeForce article.
G-Assist Gets Smarter, Expands to More RTX PCs
The modern PC is a powerhouse, but unlocking its full potential means navigating a complex maze of settings across system software, GPU and peripheral utilities, control panels and more.
Project G-Assist is a free, on-device AI assistant built to cut through that complexity. It acts as a central command center, providing easy access to functions previously buried in menus through voice or text commands. Users can ask the assistant to:
Run diagnostics to optimize game performance
Display or chart frame rates, latency and GPU temperatures
Adjust GPU or even peripheral settings, such as keyboard lighting
The G-Assist update also introduces a new, significantly more efficient AI model that’s faster and uses 40% less memory while maintaining response accuracy. The more efficient model means that G-Assist can now run on all RTX GPUs with 6GB or more VRAM, including laptops.
Getting started is simple: install the NVIDIA app and the latest Game Ready Driver on Aug. 19, download the G-Assist update from the app’s home screen and press Alt+G to activate.
Another G-Assist update coming in September will introduce support for laptop-specific commands for features like NVIDIA BatteryBoost and Battery OPS.
Introducing the G-Assist Plug-In Hub With Mod.io
NVIDIA is collaborating with mod.io to launch the G-Assist Plug-In Hub, which allows users to easily access G-Assist plug-ins, as well as discover and download community-created ones.
With the mod.io plug-in, users can ask G-Assist to discover and install new plug-ins.
With the latest update, users can also directly ask G-Assist what new plug-ins are available in the hub and install them using natural language, thanks to a mod.io plug-in.
The recent G-Assist Plug-In Hackathon showcased the incredible creativity of the G-Assist community. Here’s a sneak peek of what they came up with:
Some finalists include:
Omniplay — allows gamers to use G-Assist to research lore from online wikis or take notes in real time while gaming
Launchpad — lets gamers set, launch and toggle custom app groups on the fly to boost productivity
Flux NIM Microservice for G-Assist — allows gamers to easily generate AI images from within G-Assist, using on-device NVIDIA NIM microservices
The winners of the hackathon will be announced on Wednesday, Aug. 20.
Building custom plug-ins is simple. They’re based on a foundation of JSON and Python scripts — and the Project G-Assist Plug-In Builder helps further simplify development by enabling users to code plug-ins with natural language.
Mod It Like It’s Hot With RTX Remix
Classic PC games remain beloved for their unforgettable stories, characters and gameplay — but their dated graphics can be a barrier for new and longtime players.
NVIDIA RTX Remix enables modders to revitalize these timeless titles with the latest NVIDIA gaming technologies — bridging nostalgic gameplay with modern visuals.
Since the platform’s release, the RTX Remix modding community has grown with over 350 active projects and over 100 mods released. The mods span a catalog of beloved games like Half-Life 2, Need for Speed: Underground, Portal 2 and Deus Ex — and have amassed over 2 million downloads.
In May, NVIDIA invited modders to participate in the NVIDIA and ModDB RTX Remix Mod Contest for a chance to win in cash prizes. At Gamescom, NVIDIA announced the winners:
Best Overall RTX Mod Winner: Painkiller RTX Remix, by Binq_Adams
Best Use of RTX in a Mod Winner: Painkiller RTX Remix, by Binq_Adams
Runner-Up: Vampire: The Masquerade – Bloodlines – RTX Remaster, by Safemilk
Most Complete RTX Mod Winner: Painkiller RTX Remix, by Binq_Adams
Runner-Up: I-Ninja Remixed, by g.i.george333
Community Choice RTX Mod Winner: Call of Duty 2 RTX Remix of Carentan, by tadpole3159
These modders tapped RTX Remix and generative AI to bring their creations to life — from enhancing textures to quickly creating images and 3D assets.
For example, the Merry Pencil Studios modder team used a workflow that seamlessly connected RTX Remix and ComfyUI, allowing them to simply select textures in the RTX Remix viewport and, with a single click in ComfyUI, restore them.
The results are stunning, with each texture meticulously recreated with physically based materials layered with grime and rust. With a fully path-traced lighting system, the game’s gothic horror atmosphere has never felt more immersive to play through.
All mods submitted to the RTX Remix Modding Contest, as well as 100 more Remix mods, are available to download from ModDB. For a sneak peek at RTX Remix projects under active development, check out the RTX Remix Showcase Discord server.
Another RTX Remix update coming in September will allow modders to create new particles that match the look of those found in modern titles. This opens the door for over 165 RTX Remix-compatible games to have particles for the first time.
To get started creating RTX mods, download NVIDIA RTX Remix from the home screen of the NVIDIA app. Read the RTX Remix article to learn more about the contest and winners.
Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, productivity apps and more on AI PCs and workstations.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter. Join NVIDIA’s Discord server to connect with community developers and AI enthusiasts for discussions on what’s possible with RTX AI.
Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.
#new #lightweight #model #project #gassistNew Lightweight AI Model for Project G-Assist Brings Support for 6GB NVIDIA GeForce RTX and RTX PRO GPUsAt Gamescom, NVIDIA is releasing its first major update to Project G‑Assist — an experimental on-device AI assistant that allows users to tune their NVIDIA RTX systems with voice and text commands. The update brings a new AI model that uses 40% less VRAM, improves tool-calling intelligence and extends G-Assist support to all RTX GPUs with 6GB or more VRAM, including laptops. Plus, a new G-Assist Plug-In Hub enables users to easily discover and download plug-ins to enable more G-Assist features. NVIDIA also announced a new path-traced particle system, coming in September to the NVIDIA RTX Remix modding platform, that brings fully simulated physics, dynamic shadows and realistic reflections to visual effects. In addition, NVIDIA named the winners of the NVIDIA and ModDB RTX Remix Mod Contest. Check out the winners and finalist RTX mods in the RTX Remix GeForce article. G-Assist Gets Smarter, Expands to More RTX PCs The modern PC is a powerhouse, but unlocking its full potential means navigating a complex maze of settings across system software, GPU and peripheral utilities, control panels and more. Project G-Assist is a free, on-device AI assistant built to cut through that complexity. It acts as a central command center, providing easy access to functions previously buried in menus through voice or text commands. Users can ask the assistant to: Run diagnostics to optimize game performance Display or chart frame rates, latency and GPU temperatures Adjust GPU or even peripheral settings, such as keyboard lighting The G-Assist update also introduces a new, significantly more efficient AI model that’s faster and uses 40% less memory while maintaining response accuracy. The more efficient model means that G-Assist can now run on all RTX GPUs with 6GB or more VRAM, including laptops. Getting started is simple: install the NVIDIA app and the latest Game Ready Driver on Aug. 19, download the G-Assist update from the app’s home screen and press Alt+G to activate. Another G-Assist update coming in September will introduce support for laptop-specific commands for features like NVIDIA BatteryBoost and Battery OPS. Introducing the G-Assist Plug-In Hub With Mod.io NVIDIA is collaborating with mod.io to launch the G-Assist Plug-In Hub, which allows users to easily access G-Assist plug-ins, as well as discover and download community-created ones. With the mod.io plug-in, users can ask G-Assist to discover and install new plug-ins. With the latest update, users can also directly ask G-Assist what new plug-ins are available in the hub and install them using natural language, thanks to a mod.io plug-in. The recent G-Assist Plug-In Hackathon showcased the incredible creativity of the G-Assist community. Here’s a sneak peek of what they came up with: Some finalists include: Omniplay — allows gamers to use G-Assist to research lore from online wikis or take notes in real time while gaming Launchpad — lets gamers set, launch and toggle custom app groups on the fly to boost productivity Flux NIM Microservice for G-Assist — allows gamers to easily generate AI images from within G-Assist, using on-device NVIDIA NIM microservices The winners of the hackathon will be announced on Wednesday, Aug. 20. Building custom plug-ins is simple. They’re based on a foundation of JSON and Python scripts — and the Project G-Assist Plug-In Builder helps further simplify development by enabling users to code plug-ins with natural language. Mod It Like It’s Hot With RTX Remix Classic PC games remain beloved for their unforgettable stories, characters and gameplay — but their dated graphics can be a barrier for new and longtime players. NVIDIA RTX Remix enables modders to revitalize these timeless titles with the latest NVIDIA gaming technologies — bridging nostalgic gameplay with modern visuals. Since the platform’s release, the RTX Remix modding community has grown with over 350 active projects and over 100 mods released. The mods span a catalog of beloved games like Half-Life 2, Need for Speed: Underground, Portal 2 and Deus Ex — and have amassed over 2 million downloads. In May, NVIDIA invited modders to participate in the NVIDIA and ModDB RTX Remix Mod Contest for a chance to win in cash prizes. At Gamescom, NVIDIA announced the winners: Best Overall RTX Mod Winner: Painkiller RTX Remix, by Binq_Adams Best Use of RTX in a Mod Winner: Painkiller RTX Remix, by Binq_Adams Runner-Up: Vampire: The Masquerade – Bloodlines – RTX Remaster, by Safemilk Most Complete RTX Mod Winner: Painkiller RTX Remix, by Binq_Adams Runner-Up: I-Ninja Remixed, by g.i.george333 Community Choice RTX Mod Winner: Call of Duty 2 RTX Remix of Carentan, by tadpole3159 These modders tapped RTX Remix and generative AI to bring their creations to life — from enhancing textures to quickly creating images and 3D assets. For example, the Merry Pencil Studios modder team used a workflow that seamlessly connected RTX Remix and ComfyUI, allowing them to simply select textures in the RTX Remix viewport and, with a single click in ComfyUI, restore them. The results are stunning, with each texture meticulously recreated with physically based materials layered with grime and rust. With a fully path-traced lighting system, the game’s gothic horror atmosphere has never felt more immersive to play through. All mods submitted to the RTX Remix Modding Contest, as well as 100 more Remix mods, are available to download from ModDB. For a sneak peek at RTX Remix projects under active development, check out the RTX Remix Showcase Discord server. Another RTX Remix update coming in September will allow modders to create new particles that match the look of those found in modern titles. This opens the door for over 165 RTX Remix-compatible games to have particles for the first time. To get started creating RTX mods, download NVIDIA RTX Remix from the home screen of the NVIDIA app. Read the RTX Remix article to learn more about the contest and winners. Each week, the RTX AI Garage blog series features community-driven AI innovations and content for those looking to learn more about NVIDIA NIM microservices and AI Blueprints, as well as building AI agents, creative workflows, productivity apps and more on AI PCs and workstations. Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter. Join NVIDIA’s Discord server to connect with community developers and AI enthusiasts for discussions on what’s possible with RTX AI. Follow NVIDIA Workstation on LinkedIn and X. See notice regarding software product information. #new #lightweight #model #project #gassist2 Comments ·0 Shares -
Now We’re Talking: NVIDIA Releases Open Dataset, Models for Multilingual Speech AI
Of around 7,000 languages in the world, a tiny fraction are supported by AI language models. NVIDIA is tackling the problem with a new dataset and models that support the development of high-quality speech recognition and translation AI for 25 European languages — including languages with limited available data like Croatian, Estonian and Maltese.
These tools will enable developers to more easily scale AI applications to support global users with fast, accurate speech technology for production-scale use cases such as multilingual chatbots, customer service voice agents and near-real-time translation services. They include:
Granary, a massive, open-source corpus of multilingual speech datasets that contains around a million hours of audio, including nearly 650,000 hours for speech recognition and over 350,000 hours for speech translation.
NVIDIA Canary-1b-v2, a billion-parameter model trained on Granary for high-quality transcription of European languages, plus translation between English and two dozen supported languages.
NVIDIA Parakeet-tdt-0.6b-v3, a streamlined, 600-million-parameter model designed for real-time or large-volume transcription of Granary’s supported languages.
The paper behind Granary will be presented at Interspeech, a language processing conference taking place in the Netherlands, Aug. 17-21. The dataset, as well as the new Canary and Parakeet models, are now available on Hugging Face.
How Granary Addresses Data Scarcity
To develop the Granary dataset, the NVIDIA speech AI team collaborated with researchers from Carnegie Mellon University and Fondazione Bruno Kessler. The team passed unlabeled audio through an innovative processing pipeline powered by NVIDIA NeMo Speech Data Processor toolkit that turned it into structured, high-quality data.
This pipeline allowed the researchers to enhance public speech data into a usable format for AI training, without the need for resource-intensive human annotation. It’s available in open source on GitHub.
With Granary’s clean, ready-to-use data, developers can get a head start building models that tackle transcription and translation tasks in nearly all of the European Union’s 24 official languages, plus Russian and Ukrainian.
For European languages underrepresented in human-annotated datasets, Granary provides a critical resource to develop more inclusive speech technologies that better reflect the linguistic diversity of the continent — all while using less training data.
The team demonstrated in their Interspeech paper that, compared to other popular datasets, it takes around half as much Granary training data to achieve a target accuracy level for automatic speech recognitionand automatic speech translation.
Tapping NVIDIA NeMo to Turbocharge Transcription
The new Canary and Parakeet models offer examples of the kinds of models developers can build with Granary, customized to their target applications. Canary-1b-v2 is optimized for accuracy on complex tasks, while parakeet-tdt-0.6b-v3 is designed for high-speed, low-latency tasks.
By sharing the methodology behind the Granary dataset and these two models, NVIDIA is enabling the global speech AI developer community to adapt this data processing workflow to other ASR or AST models or additional languages, accelerating speech AI innovation.
Canary-1b-v2, available under a permissive license, expands the Canary family’s supported languages from four to 25. It offers transcription and translation quality comparable to models 3x larger while running inference up to 10x faster.
NVIDIA NeMo, a modular software suite for managing the AI agent lifecycle, accelerated speech AI model development. NeMo Curator, part of the software suite, enabled the team to filter out synthetic examples from the source data so that only high-quality samples were used for model training. The team also harnessed the NeMo Speech Data Processor toolkit for tasks like aligning transcripts with audio files and converting data into the required formats.
Parakeet-tdt-0.6b-v3 prioritizes high throughput and is capable of transcribing 24-minute audio segments in a single inference pass. The model automatically detects the input audio language and transcribes without additional prompting steps.
Both Canary and Parakeet models provide accurate punctuation, capitalization and word-level timestamps in their outputs.
on GitHub and get started with Granary on Hugging Face.
#now #were #talking #nvidia #releasesNow We’re Talking: NVIDIA Releases Open Dataset, Models for Multilingual Speech AIOf around 7,000 languages in the world, a tiny fraction are supported by AI language models. NVIDIA is tackling the problem with a new dataset and models that support the development of high-quality speech recognition and translation AI for 25 European languages — including languages with limited available data like Croatian, Estonian and Maltese. These tools will enable developers to more easily scale AI applications to support global users with fast, accurate speech technology for production-scale use cases such as multilingual chatbots, customer service voice agents and near-real-time translation services. They include: Granary, a massive, open-source corpus of multilingual speech datasets that contains around a million hours of audio, including nearly 650,000 hours for speech recognition and over 350,000 hours for speech translation. NVIDIA Canary-1b-v2, a billion-parameter model trained on Granary for high-quality transcription of European languages, plus translation between English and two dozen supported languages. NVIDIA Parakeet-tdt-0.6b-v3, a streamlined, 600-million-parameter model designed for real-time or large-volume transcription of Granary’s supported languages. The paper behind Granary will be presented at Interspeech, a language processing conference taking place in the Netherlands, Aug. 17-21. The dataset, as well as the new Canary and Parakeet models, are now available on Hugging Face. How Granary Addresses Data Scarcity To develop the Granary dataset, the NVIDIA speech AI team collaborated with researchers from Carnegie Mellon University and Fondazione Bruno Kessler. The team passed unlabeled audio through an innovative processing pipeline powered by NVIDIA NeMo Speech Data Processor toolkit that turned it into structured, high-quality data. This pipeline allowed the researchers to enhance public speech data into a usable format for AI training, without the need for resource-intensive human annotation. It’s available in open source on GitHub. With Granary’s clean, ready-to-use data, developers can get a head start building models that tackle transcription and translation tasks in nearly all of the European Union’s 24 official languages, plus Russian and Ukrainian. For European languages underrepresented in human-annotated datasets, Granary provides a critical resource to develop more inclusive speech technologies that better reflect the linguistic diversity of the continent — all while using less training data. The team demonstrated in their Interspeech paper that, compared to other popular datasets, it takes around half as much Granary training data to achieve a target accuracy level for automatic speech recognitionand automatic speech translation. Tapping NVIDIA NeMo to Turbocharge Transcription The new Canary and Parakeet models offer examples of the kinds of models developers can build with Granary, customized to their target applications. Canary-1b-v2 is optimized for accuracy on complex tasks, while parakeet-tdt-0.6b-v3 is designed for high-speed, low-latency tasks. By sharing the methodology behind the Granary dataset and these two models, NVIDIA is enabling the global speech AI developer community to adapt this data processing workflow to other ASR or AST models or additional languages, accelerating speech AI innovation. Canary-1b-v2, available under a permissive license, expands the Canary family’s supported languages from four to 25. It offers transcription and translation quality comparable to models 3x larger while running inference up to 10x faster. NVIDIA NeMo, a modular software suite for managing the AI agent lifecycle, accelerated speech AI model development. NeMo Curator, part of the software suite, enabled the team to filter out synthetic examples from the source data so that only high-quality samples were used for model training. The team also harnessed the NeMo Speech Data Processor toolkit for tasks like aligning transcripts with audio files and converting data into the required formats. Parakeet-tdt-0.6b-v3 prioritizes high throughput and is capable of transcribing 24-minute audio segments in a single inference pass. The model automatically detects the input audio language and transcribes without additional prompting steps. Both Canary and Parakeet models provide accurate punctuation, capitalization and word-level timestamps in their outputs. on GitHub and get started with Granary on Hugging Face. #now #were #talking #nvidia #releases2 Comments ·0 Shares -
NVIDIA, National Science Foundation Support Ai2 Development of Open AI Models to Drive U.S. Scientific Leadership
NVIDIA is partnering with the U.S. National Science Foundationto create an AI system that supports the development of multimodal language models for advancing scientific research in the United States.
The partnership supports the NSF Mid-Scale Research Infrastructure project, called Open Multimodal AI Infrastructure to Accelerate Science.
“Bringing AI into scientific research has been a game changer,” said Brian Stone, performing the duties of the NSF director. “NSF is proud to partner with NVIDIA to equip America’s scientists with the tools to accelerate breakthroughs. These investments are not just about enabling innovation; they are about securing U.S. global leadership in science and technology and tackling challenges once thought impossible.”
OMAI, part of the work of the Allen Institute for AI, or Ai2, aims to build a national fully open AI ecosystem to drive scientific discovery through AI, while also advancing the science of AI itself.
NVIDIA’s support of OMAI includes providing NVIDIA HGX B300 systems — state-of-the-art AI infrastructure built to accelerate model training and inference with exceptional efficiency — along with the NVIDIA AI Enterprise software platform, empowering OMAI to transform massive datasets into actionable intelligence and breakthrough innovations.
NVIDIA HGX B300 systems are built with NVIDIA Blackwell Ultra GPUs and feature industry-leading high-bandwidth memory and interconnect technologies to deliver groundbreaking acceleration, scalability and efficiency to run the world’s largest models and most demanding workloads.
“AI is the engine of modern science — and large, open models for America’s researchers will ignite the next industrial revolution,” said Jensen Huang, founder and CEO of NVIDIA. “In collaboration with NSF and Ai2, we’re accelerating innovation with state-of-the-art infrastructure that empowers U.S. scientists to generate limitless intelligence, making it America’s most powerful and renewable resource.”
The contributions will support research teams from the University of Washington, the University of Hawaii at Hilo, the University of New Hampshire and the University of New Mexico. The public-private partnership investment in U.S. technology aligns with recent initiatives outlined by the White House AI Action Plan, which supports America’s global AI leadership.
“The models are part of the national research infrastructure — but we can’t build the models without compute, and that’s why NVIDIA is so important to this project,” said Noah Smith, senior director of natural language processing research at Ai2.
Opening Language Models to Advance American Researchers
Driving some of the fastest-growing applications in history, today’s large language modelshave many billions of parameters, or internal weights and biases learned in training. LLMs are trained on trillions of words, and multimodal LLMs can ingest images, graphs, tables and more.
But the power of these so-called frontier models can sometimes be out of reach for scientific research when the parameters, training data, code and documentation are not openly available.
“With the model training data in hand, you have the opportunity to trace back to particular training instances similar to a response, and also more systematically study how emerging behaviors relate to the training data,” said Smith.
NVIDIA’s partnership with NSF to support Ai2’s OMAI initiative provides fully open model access to data, open-source data interrogation tools to help refine datasets, as well as documentation and training for early-career researchers — advancing U.S. global leadership in science and engineering.
The Ai2 project — supported by NVIDIA technologies — pledges to make the software and models available at low or zero cost to researchers, similar to open-source code repositories and science-oriented digital libraries. It’s in line with Ai2’s previous work in creating fully open language models and multimodal models, maximizing access.
Driving U.S. Global Leadership in Science and Engineering
“Winning the AI Race: America’s AI Action Plan” was announced in July by the White House, supported with executive orders to accelerate federal permitting of data center infrastructure and promote exportation of the American AI technology stack.
The OMAI initiative aligns with White House AI Action Plan priorities, emphasizing the acceleration of AI-enabled science and supporting the creation of leading open models to enhance America’s global AI leadership in academic research and education.
#nvidia #national #science #foundation #supportNVIDIA, National Science Foundation Support Ai2 Development of Open AI Models to Drive U.S. Scientific LeadershipNVIDIA is partnering with the U.S. National Science Foundationto create an AI system that supports the development of multimodal language models for advancing scientific research in the United States. The partnership supports the NSF Mid-Scale Research Infrastructure project, called Open Multimodal AI Infrastructure to Accelerate Science. “Bringing AI into scientific research has been a game changer,” said Brian Stone, performing the duties of the NSF director. “NSF is proud to partner with NVIDIA to equip America’s scientists with the tools to accelerate breakthroughs. These investments are not just about enabling innovation; they are about securing U.S. global leadership in science and technology and tackling challenges once thought impossible.” OMAI, part of the work of the Allen Institute for AI, or Ai2, aims to build a national fully open AI ecosystem to drive scientific discovery through AI, while also advancing the science of AI itself. NVIDIA’s support of OMAI includes providing NVIDIA HGX B300 systems — state-of-the-art AI infrastructure built to accelerate model training and inference with exceptional efficiency — along with the NVIDIA AI Enterprise software platform, empowering OMAI to transform massive datasets into actionable intelligence and breakthrough innovations. NVIDIA HGX B300 systems are built with NVIDIA Blackwell Ultra GPUs and feature industry-leading high-bandwidth memory and interconnect technologies to deliver groundbreaking acceleration, scalability and efficiency to run the world’s largest models and most demanding workloads. “AI is the engine of modern science — and large, open models for America’s researchers will ignite the next industrial revolution,” said Jensen Huang, founder and CEO of NVIDIA. “In collaboration with NSF and Ai2, we’re accelerating innovation with state-of-the-art infrastructure that empowers U.S. scientists to generate limitless intelligence, making it America’s most powerful and renewable resource.” The contributions will support research teams from the University of Washington, the University of Hawaii at Hilo, the University of New Hampshire and the University of New Mexico. The public-private partnership investment in U.S. technology aligns with recent initiatives outlined by the White House AI Action Plan, which supports America’s global AI leadership. “The models are part of the national research infrastructure — but we can’t build the models without compute, and that’s why NVIDIA is so important to this project,” said Noah Smith, senior director of natural language processing research at Ai2. Opening Language Models to Advance American Researchers Driving some of the fastest-growing applications in history, today’s large language modelshave many billions of parameters, or internal weights and biases learned in training. LLMs are trained on trillions of words, and multimodal LLMs can ingest images, graphs, tables and more. But the power of these so-called frontier models can sometimes be out of reach for scientific research when the parameters, training data, code and documentation are not openly available. “With the model training data in hand, you have the opportunity to trace back to particular training instances similar to a response, and also more systematically study how emerging behaviors relate to the training data,” said Smith. NVIDIA’s partnership with NSF to support Ai2’s OMAI initiative provides fully open model access to data, open-source data interrogation tools to help refine datasets, as well as documentation and training for early-career researchers — advancing U.S. global leadership in science and engineering. The Ai2 project — supported by NVIDIA technologies — pledges to make the software and models available at low or zero cost to researchers, similar to open-source code repositories and science-oriented digital libraries. It’s in line with Ai2’s previous work in creating fully open language models and multimodal models, maximizing access. Driving U.S. Global Leadership in Science and Engineering “Winning the AI Race: America’s AI Action Plan” was announced in July by the White House, supported with executive orders to accelerate federal permitting of data center infrastructure and promote exportation of the American AI technology stack. The OMAI initiative aligns with White House AI Action Plan priorities, emphasizing the acceleration of AI-enabled science and supporting the creation of leading open models to enhance America’s global AI leadership in academic research and education. #nvidia #national #science #foundation #support2 Comments ·0 Shares -
‘Warhammer 40,000: Dawn of War – Definitive Edition’ Storms GeForce NOW at Launch
Warhammer 40,000: Dawn of War – Definitive Edition is marching onto GeForce NOW, expanding the cloud gaming platform’s library to over 2,300 supported titles.
Battle is just a click away, as the iconic real-time strategy game joins seven new releases this week. Commanders can prepare their squads and steel their nerves on any device — including laptops, Macs, Steam Decks and NVIDIA SHIELD TVs.
Microsoft’s surprise announcement at Quakecon is now available in the cloud: legendary fantasy shooters Heretic + Hexen have been conjured out of the shadows and are streaming on GeForce NOW.
And don’t miss out on in-game rewards for the popular, free-to-play, massively multiplayer online game World of Tanks as publisher Wargaming celebrates the title’s 15-year anniversary.
GeForce NOW will be at Gamescom 2025 — the world’s largest gaming tradeshow — starting Wednesday, Aug. 20. Stay tuned to GFN Thursday for all the latest updates.
The Emperor’s Call
Make your victories shine from the cloud.
The grimdark future calls. Warhammer 40,000: Dawn of War – Definitive Edition storms onto the battlefield with ferocious, squad-based real-time strategy. Command the Space Marines, Orks, Chaos, Eldar and more across four legendary campaigns and nine playable armies. From bolter roars to Waaagh! cries, battles erupt with uncompromising brutality, tactical depth and a healthy dose of swagger.
Fully remastered with enhanced 4K visuals, a refined camera, an improved user interface and more, Dawn of War: Definitive Edition preserves the iconic chaos of the original game while throwing open the gates for creative mayhem. Every charge, psychic blast and last-stand is rendered sharper than ever as cunning, courage and unrelenting war decide the fate of worlds.
GeForce NOW delivers the firepower needed to join the frontlines without having to wait for downloads or lengthy installs. Gamers can leap straight into battle, resume campaigns and join multiplayer chaos with just a few clicks. No frames lost to underpowered hardware — every skirmish, every decisive strike is rendered in full glory in the cloud.
Time to Celebrate
Make your victories shine from the cloud.
Roll out the tanks for World of Tanks’s 15th-anniversary celebration. Join the party by logging into the game every day through Sunday, Aug. 31 for exclusive commemorative rewards.
Here’s what’s on deck: daily in-game giveaways, deep discounts, a pulse-pounding limited-time game mode and a special Battle Pass chapter packed with surprises. Watch for Twitch drops, enjoy increased credit earnings when playing with veteran tankers and dive into a unique photo-album event where each day reveals a new chapter in the evolution of maps, vehicles and epic memories.
Enjoy smooth, lightning-fast gameplay on GeForce NOW — even on modest hardware — and share every explosive moment with friends, fans and fellow commanders. No download hassles, just pure, seamless action.
Get Hexed
Suit up, pick a class and let chaos reign.
Step into the shadowy worlds that shaped fantasy shooters — fully restored by Nightdive Studios. Heretic + Hexen, the cult classics forged by Raven Software, are back with a vengeance, bringing their spell-slinging attitude and dark magic to a whole new generation.
This definitive collection brings together Heretic: Shadow of the Serpent Riders, Hexen: Beyond Heretic and Hexen: Deathkings of the Dark Citadel — plus two brand-new episodes, Heretic: Faith Renewed and Hexen: Vestiges of Grandeur, crafted with id Software and Nightdive Studios.
Dive into over 110 campaign maps, 120 deathmatch arenas, online and split-screen multiplayer modes, 4K 120 frames-per-secondvisuals, modern controls and more spell-slinging action than ever.
Experience the arcane might of Heretic + Hexen with GeForce NOW, which offers instant gameplay on nearly any device, with cloud-powered graphics, ultrasmooth performance and zero downloads. Ultimate members can crank up the magic and stream at up to 4K 120 fps — even without the latest hardware, so every exploding tome and fireball looks spellbindingly sharp.
All Aboard for New Games
Outwit the future.
All aboard, Trailblazers. Honkai Star Rail’s new Version 3.5 “Before Their Deaths” is available to stream on GeForce NOW — no need to wait for patches or updates to downloads.
The latest version brings two new playable characters, Hysilens and Imperator Cerydra, who bring fresh abilities and strategies to the game. Journey back a thousand years to ancient Okhema, face the ever-shifting menace Lygus and explore the dazzling streets of Styxia, the City of Infinite Revelry. Between epic battles, serve fairy patrons in the Chrysos Maze Grand Restaurant, mix drinks with old friends and uncover secrets that could change everything. Get ready — the next stop on the Astral Express is about to be unforgettable.
In addition, members can look for the following:
Echoes of the End9 KingsWarhammer 40,000: Dawn of War – Definitive EditionSupraworldCrash Bandicoot 4: It’s About TimeGuntouchablesHeretic + HexenWhat are you planning to play this weekend? Let us know on X or in the comments below.
What's a classic game that you still love to play?
— NVIDIA GeForce NOWAugust 13, 2025
#warhammer #dawn #war #definitive #edition‘Warhammer 40,000: Dawn of War – Definitive Edition’ Storms GeForce NOW at LaunchWarhammer 40,000: Dawn of War – Definitive Edition is marching onto GeForce NOW, expanding the cloud gaming platform’s library to over 2,300 supported titles. Battle is just a click away, as the iconic real-time strategy game joins seven new releases this week. Commanders can prepare their squads and steel their nerves on any device — including laptops, Macs, Steam Decks and NVIDIA SHIELD TVs. Microsoft’s surprise announcement at Quakecon is now available in the cloud: legendary fantasy shooters Heretic + Hexen have been conjured out of the shadows and are streaming on GeForce NOW. And don’t miss out on in-game rewards for the popular, free-to-play, massively multiplayer online game World of Tanks as publisher Wargaming celebrates the title’s 15-year anniversary. GeForce NOW will be at Gamescom 2025 — the world’s largest gaming tradeshow — starting Wednesday, Aug. 20. Stay tuned to GFN Thursday for all the latest updates. The Emperor’s Call Make your victories shine from the cloud. The grimdark future calls. Warhammer 40,000: Dawn of War – Definitive Edition storms onto the battlefield with ferocious, squad-based real-time strategy. Command the Space Marines, Orks, Chaos, Eldar and more across four legendary campaigns and nine playable armies. From bolter roars to Waaagh! cries, battles erupt with uncompromising brutality, tactical depth and a healthy dose of swagger. Fully remastered with enhanced 4K visuals, a refined camera, an improved user interface and more, Dawn of War: Definitive Edition preserves the iconic chaos of the original game while throwing open the gates for creative mayhem. Every charge, psychic blast and last-stand is rendered sharper than ever as cunning, courage and unrelenting war decide the fate of worlds. GeForce NOW delivers the firepower needed to join the frontlines without having to wait for downloads or lengthy installs. Gamers can leap straight into battle, resume campaigns and join multiplayer chaos with just a few clicks. No frames lost to underpowered hardware — every skirmish, every decisive strike is rendered in full glory in the cloud. Time to Celebrate Make your victories shine from the cloud. Roll out the tanks for World of Tanks’s 15th-anniversary celebration. Join the party by logging into the game every day through Sunday, Aug. 31 for exclusive commemorative rewards. Here’s what’s on deck: daily in-game giveaways, deep discounts, a pulse-pounding limited-time game mode and a special Battle Pass chapter packed with surprises. Watch for Twitch drops, enjoy increased credit earnings when playing with veteran tankers and dive into a unique photo-album event where each day reveals a new chapter in the evolution of maps, vehicles and epic memories. Enjoy smooth, lightning-fast gameplay on GeForce NOW — even on modest hardware — and share every explosive moment with friends, fans and fellow commanders. No download hassles, just pure, seamless action. Get Hexed Suit up, pick a class and let chaos reign. Step into the shadowy worlds that shaped fantasy shooters — fully restored by Nightdive Studios. Heretic + Hexen, the cult classics forged by Raven Software, are back with a vengeance, bringing their spell-slinging attitude and dark magic to a whole new generation. This definitive collection brings together Heretic: Shadow of the Serpent Riders, Hexen: Beyond Heretic and Hexen: Deathkings of the Dark Citadel — plus two brand-new episodes, Heretic: Faith Renewed and Hexen: Vestiges of Grandeur, crafted with id Software and Nightdive Studios. Dive into over 110 campaign maps, 120 deathmatch arenas, online and split-screen multiplayer modes, 4K 120 frames-per-secondvisuals, modern controls and more spell-slinging action than ever. Experience the arcane might of Heretic + Hexen with GeForce NOW, which offers instant gameplay on nearly any device, with cloud-powered graphics, ultrasmooth performance and zero downloads. Ultimate members can crank up the magic and stream at up to 4K 120 fps — even without the latest hardware, so every exploding tome and fireball looks spellbindingly sharp. All Aboard for New Games Outwit the future. All aboard, Trailblazers. Honkai Star Rail’s new Version 3.5 “Before Their Deaths” is available to stream on GeForce NOW — no need to wait for patches or updates to downloads. The latest version brings two new playable characters, Hysilens and Imperator Cerydra, who bring fresh abilities and strategies to the game. Journey back a thousand years to ancient Okhema, face the ever-shifting menace Lygus and explore the dazzling streets of Styxia, the City of Infinite Revelry. Between epic battles, serve fairy patrons in the Chrysos Maze Grand Restaurant, mix drinks with old friends and uncover secrets that could change everything. Get ready — the next stop on the Astral Express is about to be unforgettable. In addition, members can look for the following: Echoes of the End9 KingsWarhammer 40,000: Dawn of War – Definitive EditionSupraworldCrash Bandicoot 4: It’s About TimeGuntouchablesHeretic + HexenWhat are you planning to play this weekend? Let us know on X or in the comments below. What's a classic game that you still love to play? — NVIDIA GeForce NOWAugust 13, 2025 #warhammer #dawn #war #definitive #edition2 Comments ·0 Shares -
Applications Now Open for $60,000 NVIDIA Graduate Fellowship Awards
Bringing together the world’s brightest minds and the latest accelerated computing technology leads to powerful breakthroughs that help tackle some of the biggest research problems.
To foster such innovation, the NVIDIA Graduate Fellowship Program provides grants, mentors and technical support to doctoral students doing outstanding research relevant to NVIDIA technologies. The program, in its 25th year, is now accepting applications worldwide.
It focuses on supporting students working in AI, machine learning, autonomous vehicles, computer graphics, robotics, healthcare, high-performance computing and related fields. Awards are up to per student.
Since its start in 2002, the Graduate Fellowship Program has awarded over 200 grants worth more than million.
Students must have completed at least their first year of Ph.D.-level studies at the time of application.
The application deadline for the 2026-2027 academic year is Monday, Sept. 15, 2025. An in-person internship at an NVIDIA research office preceding the fellowship year is mandatory; eligible candidates must be available for the internship in summer 2026.
For more on eligibility and how to apply, visit the program website.
#applications #now #open #nvidia #graduateApplications Now Open for $60,000 NVIDIA Graduate Fellowship AwardsBringing together the world’s brightest minds and the latest accelerated computing technology leads to powerful breakthroughs that help tackle some of the biggest research problems. To foster such innovation, the NVIDIA Graduate Fellowship Program provides grants, mentors and technical support to doctoral students doing outstanding research relevant to NVIDIA technologies. The program, in its 25th year, is now accepting applications worldwide. It focuses on supporting students working in AI, machine learning, autonomous vehicles, computer graphics, robotics, healthcare, high-performance computing and related fields. Awards are up to per student. Since its start in 2002, the Graduate Fellowship Program has awarded over 200 grants worth more than million. Students must have completed at least their first year of Ph.D.-level studies at the time of application. The application deadline for the 2026-2027 academic year is Monday, Sept. 15, 2025. An in-person internship at an NVIDIA research office preceding the fellowship year is mandatory; eligible candidates must be available for the internship in summer 2026. For more on eligibility and how to apply, visit the program website. #applications #now #open #nvidia #graduate4 Comments ·0 Shares





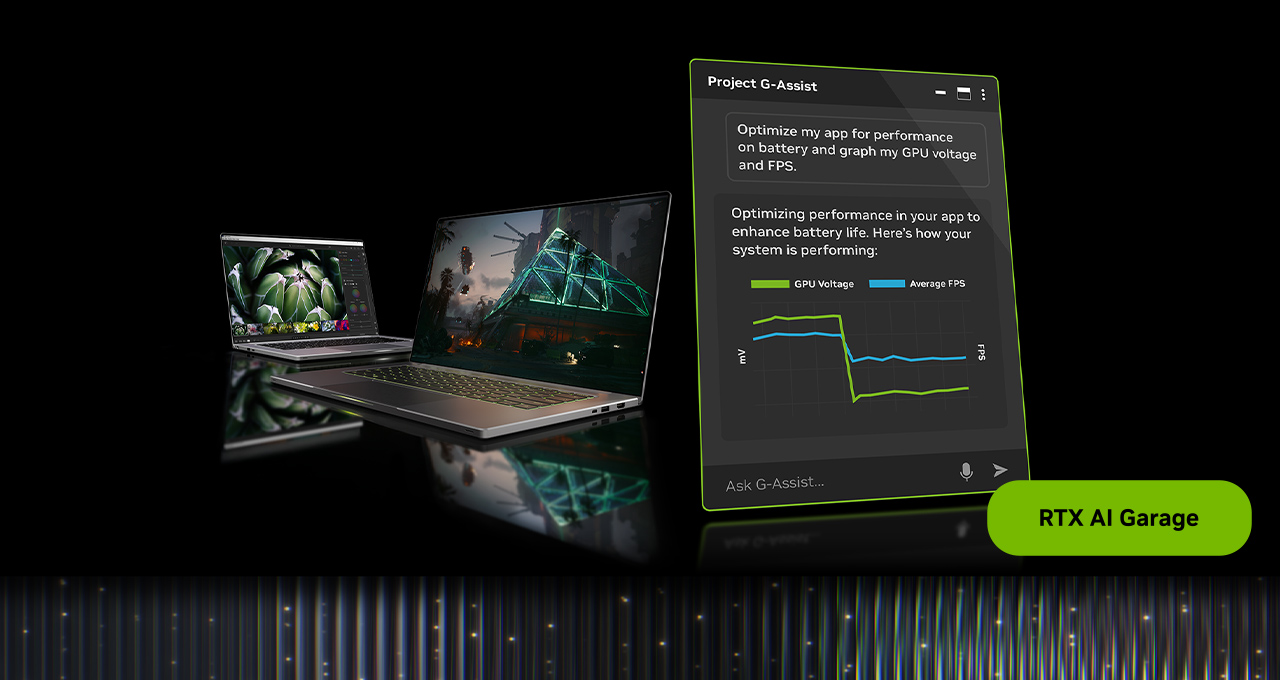

More Stories
